At long last, I'm back on the ANTLR v4 rebuild after 9 months hiatus to write an academic LL(*) paper with Kathleen Fisher and release StringTemplate v4. Woot!
Ok, so what does all that title nonsense have to do with ANTLR v4? Well, v4 will use all those things at some point, either in analysis or in the generated code. I'm proposing something a little different for v4: Along with a recursive-descent parser, I'm going to serialize the grammar down to a simple PDA (push-down automaton) represented by the bytecodes of an interpreter (Derived partially from Cox' description of Thompson's 1960s work). The interpreter will serve many useful purposes:
- a pure interpreted version of a lexer/parser/tree parser; related work: A Text Pattern-Matching Tool based on Parsing Expression Grammars, but I will need to extend for semantic predicates and actions
- the backtracking mechanism for parsers and tree parsers
- the mechanism for handling lexical constructs that a DFA cannot handle.
- improve error recovery
- support "code completion / intellisense" type functionality in development environments
From the bytecodes, we can build a data structure in memory that will be more convenient for a lot of purposes. The data structure will effectively be a recursive transition network (RTN) or, if there are predicates and actions, an augmented transition network (ATN).
Pure-interpreted parsing
Sometimes you need to parse some data but going through the whole ANTLR code generation and then compilation process is overkill. It would be nice to have a good interpreter that could parse input described by a grammar without having to deal with code generation. We can short-circuit the ANTLR tool at the point it's created an internal ATN but before code generation. Then, we can simply run an interpreter over the ATN.
If you don't mind a code generation phase but don't want a huge output file typical of recursive descent parsers, we could also generate the bytecode for a PDA into a Java file. The bytecodes are like a serialized version of the ATN. Even if you don't plan on interpreting the grammar, I think I will generate the bytecodes anyway for the recovery stuff I describe below. The bytecodes even for large grammar shouldn't be more than a few k or 10s of k bytes. Hmm... this does bring up the whole issue again in Java of generating static arrays (see Implementing parsers and state machines in Java).
Interpreted backtracking
Unlike most backtracking parsers, ANTLR v3 supports arbitrary actions, even those that cannot be undone. It does that by turning off the actions while backtracking. Upon success, it rewinds the input and then re-parses the input, this time with feeling to execute the actions. To pull this off, I need to generate an "if backtracking" conditional around every action, which causes a problem if you've defined a local variable in that action. All of a sudden that variable is invisible to the other actions. Also, at least the way I generate syntactic predicates in v3, backtracking results in code bloat.
If I have a separate mechanism to do backtracking, I don't need to guard all of the actions with a conditional and there's no code bloat. Syntactic predicates will launch an interpreter (as bytecodes or walking an ATN; doesn't matter) to see if a particular grammar fragment matches. Even if this turns out to be much lower than using generated recursive descent code fragments, ANTLR works very hard to remove unnecessary syntactic predicates. I doubt even a slow implementation would affect the overall parsing time significantly.
Handling context-free fragments in the lexer
ANTLR v3 lexers annoy me and probably you too. v4 lexers will be DFA-based and, theoretically, should be much faster as a result. Further, they will also behave much more as people expect in some edge cases. (I'm adding modes since they are really useful for parsing HTML and other embedded languages). The problem is I really want to support non-greedy operators, which are really hard to implement in a conventional DFA but trivial in an NFA/ATN. I also want to allow arbitrary actions interspersed among the rule elements. Oh, and recursion. What this comes down to is using the DFA as an optimization if you don't do anything wacky. If you come up with a rule that's recursive or has actions and non-right edges or non-greedy operators, ANTLR generates PDA bytecodes for those rules and, importantly, any rules that look like they could match the same thing. Upon entry to nextToken(), the lexer uses the current character to determine whether to jump to the PDA or the DFA. Oh, I almost forgot--Unicode characters can cause trouble in terms of table size for pure DFA. Range 'a'..'\u8000' for example, makes a transition table 0x8000 elements big for each state that could reference it. It makes more sense to deal with Unicode with a separate mechanism. I think JavaCC does this too.
Better error recovery
If we have a mapping from every location in the grammar to a position in an ATN, we should be able to do a pretty good job of error recovery. For example, we can supply error alternatives without bloating the generated code at all. Here is a contrived example with two regular alternatives and two error alternatives:
stat: 'return' expr ';'
| ID '(' args ')' ';'
/ 'return' ';' // missing expr
/ ';' // missing statement
;
If there's a syntax error, we can suspend the parser and launch an interpreter that tries to match one of the error alternatives. If one succeeds, an action in that alternative will properly report an error and resynchronize. If nothing matches, we can do the standard recovery boogie.
The standard error recovery is to compute the set of possible following symbols, using the parsing stack as context to provide the exact follow rather than FOLLOW(the-rule). If we have the entire grammar represented in some way, ANTLR does not have to compute and then generate code to store bits sets for error recovery. I can just walk the ATN at runtime. It also doesn't have to pass these bits it's around as it does in v3. For rule reference r, currently I need to generate:
pushFollow(FOLLOW_r_set_for_this_ref_position); r(); state._fsp--;
Likely I will need to keep some kind of pointer and stack of pointers into the ATN representation of the grammar in order to pull off this error recovery.
Code completion
Beyond error recovery, we can provide good information to the user about what the parser could've accepted at any particular error position.
After reading more about whitespace handling in scannerless parsing generators (e.g., GLR, PEG), it looks like you have to manually insert references to whitespace rules after every "token rule" and one at the beginning of the parse. So apparently, ANTLR is a scannerless parser generator if you simply use characters as tokens. ![]() This page shows not only how to build a real scannerless parser in antlr but also shows how to build abstract syntax trees (i.e., not parse trees)!
This page shows not only how to build a real scannerless parser in antlr but also shows how to build abstract syntax trees (i.e., not parse trees)!
Scannerless parser
Here is the grammar from before updated with whitespace handling and keyword checking in rule id.
grammar T;
@header {
import java.util.Set;
import java.util.HashSet;
}
@members {
public static Set<String> keywords = new HashSet<String>() {{
add("return");
}};
}
prog: ws? stat+ EOF ;
stat: kreturn e semi
| id eq e semi
| id colon
;
e : integer | id ;
id : letter+ {!keywords.contains($text)}? ws? ;
eq : '=' ws? ;
colon: ':' ws? ;
semi: ';' ws? ;
kreturn : 'r' 'e' 't' 'u' 'r' 'n' ws? ;
integer : digit+ ws? ;
digit
: '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'
;
letter
: 'a' | 'b' | 'c' | 'd' | 'e' | 'f' | 'g' | 'h' | 'i' | 'j'
| 'k' | 'l' | 'm' | 'n' | 'o' | 'p' | 'q' | 'r' | 's' | 't'
| 'u' | 'v' | 'w' | 'x' | 'y' | 'z'
;
ws : (' ' | '\t' | '\n' | comment)+ ;
comment : '//' ~'\n'* '\n' ;
Given input
// start return 23; // foo a = b; // end
ANTLRWorks reports the following parse tree:

The other problem is to avoid matching keywords as identifiers, which we can handle with a semantic predicate. Oddly enough, we can do it without a predicate that gets hoisted into the decision-making process. The predicate in rule id makes sure that we have not found a keyword. Given input:
return = 3;
we get a bad, but correct error message:
line 1:6 rule id failed predicate: {!keywords.contains($text)}?
Notice that, because the predicate appears after letter+, there is no way it gets hoisted into the prediction for rule stat. It turns out that syntax alone is enough to distinguish the alternatives because "return" it is always followed by an expression but not by '=' or ':'. The order of the alternatives in stat does not matter; LL(*) correctly handles the decision.
What if we have two syntactically identical alternatives where the left edges start with a keyword and an identifier?
foo : kreturn semi | id semi ;
ANTLR reports the syntactic ambiguity:
warning(200): T.g:21:5: Decision can match input such as "'r' 'e' 't' 'u' 'r' 'n' ' ' ';'"
using multiple alternatives: 1, 2
As a result, alternative(s) 2 were disabled for that input
It resolves it correctly, however, because priority is given to the first alternative. If we swap the order of the alternatives, though, "return" would match as an identifier. We could fix this with a semantic predicate, but it would be awkward in this scannerless mode. The predicate would have to march ahead to match an identifier and then test it against the keyword list. The validating predicate we have above in rule id checks the text after we've matched the identifier.
To do this for real, I think I would make ANTLR deal explicitly with scannerless grammars so that it could automatically add "ws?" on the end of any token rule. we already have the notion of a token rule, anything starting with an uppercase letter. So if you define
SEMI : ';' ;
Then ANTLR would automatically insert WS? on the end of that rule. You can also optimize any backtracking or memoization that had to happen, since it knows that the rule is really a token.
Oh, you want AST construction?
The usual ANTLR AST construction mechanism works too, but it's a little bit more work because the individual elements are characters not tokens. Here I have defined a few imaginary tokens for use as AST nodes. For input:
// start return 23; // foo foo = bar; // end
we want AST:
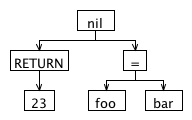
Here is the grammar with AST construction modifications:
parser grammar T;
options {output=AST;}
tokens {RETURN; ID; INT;}
@header {
import java.util.Set;
import java.util.HashSet;
}
@members {
public static Set<String> keywords = new HashSet<String>() {{
add("return");
}};
}
prog: ws? stat+ EOF -> stat+ ;
stat: kreturn e semi -> ^(kreturn e)
| id eq e semi -> ^(eq id e)
| id colon -> id
;
e : integer | id ;
id : letter+ {!keywords.contains($text)}? ws? -> ID[$text.trim()] ;
eq : '=' ws? -> '=' ;
colon: ':' ws? -> ':' ;
semi: ';' ws? -> ';' ;
kreturn : 'r' 'e' 't' 'u' 'r' 'n' ws? -> RETURN ;
integer : digit+ ws? -> INT[$text.trim()] ;
digit
: '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'
;
letter
: 'a' | 'b' | 'c' | 'd' | 'e' | 'f' | 'g' | 'h' | 'i' | 'j'
| 'k' | 'l' | 'm' | 'n' | 'o' | 'p' | 'q' | 'r' | 's' | 't'
| 'u' | 'v' | 'w' | 'x' | 'y' | 'z'
;
ws : (' ' | '\t' | '\n' | comment)+ ;
comment : '//' ~'\n'* '\n' ;
PS: woot!
Scannerless parsing generators have an advantage over separate lexers and parsers: it's much easier to create Island grammars, combine components of grammars, and deal with context-sensitive lexical constructs. I still think I prefer tokenizing the input, but thought I would run an experiment to see what a scannerless ANTLR grammar would look like.
I started out with the grammar that contained an LL(*) but non-LL(k) rule (stat). Because we're looking at characters as tokens, referencing rule id on the left edge of the second two alternatives of stat represents an infinite, left prefix. id also conflicts with the keyword rule kreturn. Here's the grammar:
parser grammar T; prog: stat+ EOF ; stat: kreturn e ';' | id '=' e ';' | id ':' ; e : integer | id ; id : letter+ ; kreturn : 'r' 'e' 't' 'u' 'r' 'n' ; integer : digit+ ; digit : '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9' ; letter : 'a' | 'b' | 'c' | 'd' | 'e' | 'f' | 'g' | 'h' | 'i' | 'j' | 'k' | 'l' | 'm' | 'n' | 'o' | 'p' | 'q' | 'r' | 's' | 't' | 'u' | 'v' | 'w' | 'x' | 'y' | 'z' ;
The DFA that predicts alternatives of rule stat looks complicated, but it's really just trying to see past the letters to the characters that follow. LL(*) handles this with no problem but LL(k), with its fixed k lookahead, couldn't predict alternatives. Here is the DFA:
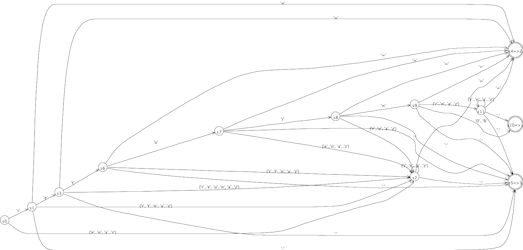
The trick to making this work is to create a stream of tokens that are really characters. The problem is that, since were making a parser grammar not a lexer grammar, ANTLR thinks that the character 'a' is really some random token type instead of the ASCII code. Using the tokenNames array in the generated parser, the following class figures out what the right token type is for each input character.
import org.antlr.runtime.CharStream;
import org.antlr.runtime.CommonToken;
import org.antlr.runtime.Token;
import org.antlr.runtime.TokenSource;
import org.antlr.tool.Grammar;
import java.util.LinkedHashMap;
import java.util.Map;
public class CharsAsTokens implements TokenSource {
CharStream input;
String[] tokenNames;
int line=1;
int charPosInLine;
Map<Integer, Integer> charToTokenType = new LinkedHashMap<Integer, Integer>();
public CharsAsTokens(CharStream input, String[] tokenNames) {
this.input = input;
this.tokenNames = tokenNames;
int ttype = 0;
for (String tname : tokenNames) {
if ( tname.charAt(0)=='\'' ) {
charToTokenType.put(Grammar.getCharValueFromGrammarCharLiteral(tname), ttype);
}
ttype++;
}
System.out.println(charToTokenType);
}
public Token nextToken() {
Token t = null;
consumeUnknown();
int c = input.LA(1);
int i = input.index();
if ( c == CharStream.EOF ) {
t = Token.EOF_TOKEN;
}
else {
Integer ttypeI = charToTokenType.get(c);
t = new CommonToken(input, ttypeI, Token.DEFAULT_CHANNEL, i, i);
}
t.setLine(line);
t.setCharPositionInLine(charPosInLine);
consume();
return t;
}
protected void consumeUnknown() {
int c = input.LA(1);
Integer ttypeI = charToTokenType.get(c);
while ( ttypeI==null && c != CharStream.EOF ) {
System.err.println("no token type for char '"+(char)c+"'");
c = consume();
ttypeI = charToTokenType.get(c);
}
}
protected int consume() {
int c = input.LA(1);
input.consume();
if ( c == '\n' ) { charPosInLine = 0; line++; }
charPosInLine++;
return input.LA(1);
}
public String getSourceName() {
return null;
}
}
To try this out, the following test rig works. The only difference is that we are using a weird kind of lexer:
import org.antlr.runtime.*;
public class Test {
public static void main(String[] args) throws Exception {
CharStream in = null;
if ( args.length>0 ) in = new ANTLRFileStream(args[0]);
else in = new ANTLRInputStream(System.in);
CharsAsTokens fauxLexer = new CharsAsTokens(in, T.tokenNames);
CommonTokenStream tokens = new CommonTokenStream(fauxLexer);
tokens.fill();
System.out.println(tokens.getTokens());
T parser = new T(tokens);
parser.prog();
}
}
For input:
return 23; a = b;
We get the following output (the hash table printed out first is the mapping of ASCII code to token type). we ignore any input character for which the grammar has no reference, such as newline whitespace. Finally, I print out the token list before parsing and then, generating with the trace option, we see the entry and exit rule events during the parse:
$ java org.antlr.Tool T.g
$ javac *.java
$ java Test input
{48=4, 49=5, 50=6, 51=7, 52=8, 53=9, 54=10, 55=11, 56=12, 57=13, 59=14, 61=15, 97=16, 98=17, 99=18, 100=19, 101=20, 110=21, 114=22, 116=23, 117=24}
no token type for char ' '
no token type for char '
'
no token type for char ' '
no token type for char ' '
no token type for char '
'
[[@0,0:0='r',<22>,1:0], [@1,1:1='e',<20>,1:1], [@2,2:2='t',<23>,1:2], [@3,3:3='u',<24>,1:3], [@4,4:4='r',<22>,1:4], [@5,5:5='n',<21>,1:5], [@6,7:7='2',<6>,1:7], [@7,8:8='3',<7>,1:8], [@8,9:9=';',<14>,1:9], [@9,11:11='a',<16>,2:1], [@10,13:13='=',<15>,2:3], [@11,15:15='b',<17>,2:5], [@12,16:16=';',<14>,2:6], [@13,0:0='<no text>',<-1>,3:1]]
enter prog [@0,0:0='r',<22>,1:0]
enter stat [@0,0:0='r',<22>,1:0]
enter kreturn [@0,0:0='r',<22>,1:0]
exit kreturn [@6,7:7='2',<6>,1:7]
enter e [@6,7:7='2',<6>,1:7]
enter integer [@6,7:7='2',<6>,1:7]
enter digit [@6,7:7='2',<6>,1:7]
exit digit [@7,8:8='3',<7>,1:8]
enter digit [@7,8:8='3',<7>,1:8]
exit digit [@8,9:9=';',<14>,1:9]
exit integer [@8,9:9=';',<14>,1:9]
exit e [@8,9:9=';',<14>,1:9]
exit stat [@9,11:11='a',<16>,2:1]
enter stat [@9,11:11='a',<16>,2:1]
enter id [@9,11:11='a',<16>,2:1]
enter letter [@9,11:11='a',<16>,2:1]
exit letter [@10,13:13='=',<15>,2:3]
exit id [@10,13:13='=',<15>,2:3]
enter e [@11,15:15='b',<17>,2:5]
enter id [@11,15:15='b',<17>,2:5]
enter letter [@11,15:15='b',<17>,2:5]
exit letter [@12,16:16=';',<14>,2:6]
exit id [@12,16:16=';',<14>,2:6]
exit e [@12,16:16=';',<14>,2:6]
exit stat [@13,0:0='<no text>',<-1>,3:1]
exit prog [@14,0:0='<no text>',<-1>,3:2]
I just tested the new version of ANTLR that uses ST v4 not v3. In terms of code generation, it's just about twice as fast given plenty of memory (750M). To process Jim Idle's 15296 line TSQL grammar, it takes 1760ms instead of 3624ms, though that doesn't alter the overall wall clock performance much. It still takes about 12 seconds to process the grammar. It generates a whopping 168,677 lines of Java code (not including the lexer). That gives us about 95,830 generated lines of code per second versus 46,540 lines per second previously.
Given more restrictive memory, 175M, it's a completely different story. The wall clock for ANTLR with ST v4 on TSQL is only about 15.5s vs 24s for the version with ST v3. Looking at just the code generation component, ST v4 generates code in 2667ms vs 11394ms. It's about 4.2x faster with restricted memory ![]() This can matter if you use ST in a larger application that needs lots of RAM. I took the ram up to 230M before the ST v3 version was able to complete without speed problems from memory pressure.
This can matter if you use ST in a larger application that needs lots of RAM. I took the ram up to 230M before the ST v3 version was able to complete without speed problems from memory pressure.
So, ST v4 seems to be about 2x faster than v3 when there's no memory pressure / GC thrashing. With memory constraints, ST v4 is much faster because it seems to use less memory.