Updated Sample Context-sensitive Lexer in ANTLR v3
After reading more about whitespace handling in scannerless parsing generators (e.g., GLR, PEG), it looks like you have to manually insert references to whitespace rules after every "token rule" and one at the beginning of the parse. So apparently, ANTLR is a scannerless parser generator if you simply use characters as tokens. ![]() This page shows not only how to build a real scannerless parser in antlr but also shows how to build abstract syntax trees (i.e., not parse trees)!
This page shows not only how to build a real scannerless parser in antlr but also shows how to build abstract syntax trees (i.e., not parse trees)!
Scannerless parser
Here is the grammar from before updated with whitespace handling and keyword checking in rule id.
grammar T;
@header {
import java.util.Set;
import java.util.HashSet;
}
@members {
public static Set<String> keywords = new HashSet<String>() {{
add("return");
}};
}
prog: ws? stat+ EOF ;
stat: kreturn e semi
| id eq e semi
| id colon
;
e : integer | id ;
id : letter+ {!keywords.contains($text)}? ws? ;
eq : '=' ws? ;
colon: ':' ws? ;
semi: ';' ws? ;
kreturn : 'r' 'e' 't' 'u' 'r' 'n' ws? ;
integer : digit+ ws? ;
digit
: '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'
;
letter
: 'a' | 'b' | 'c' | 'd' | 'e' | 'f' | 'g' | 'h' | 'i' | 'j'
| 'k' | 'l' | 'm' | 'n' | 'o' | 'p' | 'q' | 'r' | 's' | 't'
| 'u' | 'v' | 'w' | 'x' | 'y' | 'z'
;
ws : (' ' | '\t' | '\n' | comment)+ ;
comment : '//' ~'\n'* '\n' ;
Given input
// start return 23; // foo a = b; // end
ANTLRWorks reports the following parse tree:

The other problem is to avoid matching keywords as identifiers, which we can handle with a semantic predicate. Oddly enough, we can do it without a predicate that gets hoisted into the decision-making process. The predicate in rule id makes sure that we have not found a keyword. Given input:
return = 3;
we get a bad, but correct error message:
line 1:6 rule id failed predicate: {!keywords.contains($text)}?
Notice that, because the predicate appears after letter+, there is no way it gets hoisted into the prediction for rule stat. It turns out that syntax alone is enough to distinguish the alternatives because "return" it is always followed by an expression but not by '=' or ':'. The order of the alternatives in stat does not matter; LL(*) correctly handles the decision.
What if we have two syntactically identical alternatives where the left edges start with a keyword and an identifier?
foo : kreturn semi | id semi ;
ANTLR reports the syntactic ambiguity:
warning(200): T.g:21:5: Decision can match input such as "'r' 'e' 't' 'u' 'r' 'n' ' ' ';'"
using multiple alternatives: 1, 2
As a result, alternative(s) 2 were disabled for that input
It resolves it correctly, however, because priority is given to the first alternative. If we swap the order of the alternatives, though, "return" would match as an identifier. We could fix this with a semantic predicate, but it would be awkward in this scannerless mode. The predicate would have to march ahead to match an identifier and then test it against the keyword list. The validating predicate we have above in rule id checks the text after we've matched the identifier.
To do this for real, I think I would make ANTLR deal explicitly with scannerless grammars so that it could automatically add "ws?" on the end of any token rule. we already have the notion of a token rule, anything starting with an uppercase letter. So if you define
SEMI : ';' ;
Then ANTLR would automatically insert WS? on the end of that rule. You can also optimize any backtracking or memoization that had to happen, since it knows that the rule is really a token.
Oh, you want AST construction?
The usual ANTLR AST construction mechanism works too, but it's a little bit more work because the individual elements are characters not tokens. Here I have defined a few imaginary tokens for use as AST nodes. For input:
// start return 23; // foo foo = bar; // end
we want AST:
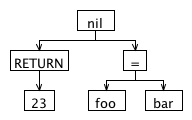
Here is the grammar with AST construction modifications:
parser grammar T;
options {output=AST;}
tokens {RETURN; ID; INT;}
@header {
import java.util.Set;
import java.util.HashSet;
}
@members {
public static Set<String> keywords = new HashSet<String>() {{
add("return");
}};
}
prog: ws? stat+ EOF -> stat+ ;
stat: kreturn e semi -> ^(kreturn e)
| id eq e semi -> ^(eq id e)
| id colon -> id
;
e : integer | id ;
id : letter+ {!keywords.contains($text)}? ws? -> ID[$text.trim()] ;
eq : '=' ws? -> '=' ;
colon: ':' ws? -> ':' ;
semi: ';' ws? -> ';' ;
kreturn : 'r' 'e' 't' 'u' 'r' 'n' ws? -> RETURN ;
integer : digit+ ws? -> INT[$text.trim()] ;
digit
: '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'
;
letter
: 'a' | 'b' | 'c' | 'd' | 'e' | 'f' | 'g' | 'h' | 'i' | 'j'
| 'k' | 'l' | 'm' | 'n' | 'o' | 'p' | 'q' | 'r' | 's' | 't'
| 'u' | 'v' | 'w' | 'x' | 'y' | 'z'
;
ws : (' ' | '\t' | '\n' | comment)+ ;
comment : '//' ~'\n'* '\n' ;
PS: woot!