Pie
This section was originally in the Language Implementation Patterns book, but I decided it was a bit advanced and not as commonly used as some other patterns. Check out the book for more interpreters, including bytecode interpreters:

Syntax-directed interpreter for the Pie language
Pattern: A syntax-directed interpreter directly executes source code without building an intermediate representation and without translating it to another language.
This page provides a sample implementation for a dynamically-typed Python-like language called Pie. It's a wee bit complicated because the memory spaces do dual duty as scopes and variable storage. It also has to switch between immediate and deferred execution (like PostScript does). The source is available as an attachment to this page.
A syntax-directed interpreter mimics what we do when we trace source code manually. As we step through the code, we parse, validate, and execute instructions. Everything happens in the parser because a syntax-directed interpreter doesn't create an AST or translate the source code to bytecodes or machine code. The interpreter directly feeds off of syntax to execute statements.
The good news is that there are very few ``moving parts'' in a syntax-directed interpreter. This sample Pie implementation is only 500 lines of Java and ANTLR code, for example. (That said, they can be pretty complicated because we're trying to do everything at once.) Here are the four key components in this interpreter:
- source code parser. The parser recognizes input construct and immediately triggers actions in the interpreter via implementation methods like
whileloop()andassign().
- interpreter. The interpreter maintains state and houses instruction action methods. There's very little state to keep track of. The interpreter has code memory, a global memory area, a stack of function memory spaces (to hold parameters and local variables), and a ``current space'' pointer. The complete buffer of input tokens represents the code memory. (An index into the token buffer acts like a code memory address.)
- symbol. We need a symbol object for each function and
structdefinition in order to track parameter and fields lists. We don't need a symbol object to hold variables since we're only tracking names. (There's no static type information in our dynamically-typed language.)
- memory space. A memory space is basically a dictionary that holds name-value pairs for variables and fields. We'll organize our spaces per Section ``Designing high-level interpreter memory systems'' in Language Implementation Patterns. As we'll see below, memory spaces also hold name-symbol pairs for functions and
structdefinitions.
Since the parser drives everything in our interpreter, let's start by seeing how it acts like a CPU.
Driving the interpreter with syntax
To interpret an input construct, the parser triggers an action method that implements the appropriate functionality. This means that the grammar (or handbuilt parser) looks like a bunch of ``match this, call that'' pairs. So, for example, when we see an assignment, we want to call an assign() action method in the interpreter. In an ANTLR grammar-based implementation, we might have rules like this:
assignment : ID '=' expr {interp.assign($ID, $expr.value);} ;
expr returns [Object value] : ... ; // compute and return value
There is an action method for every statement and expression operation. For example, here is the algorithm to perform an assignment:
void assign(String id, Object value) { // execute "id = value"
MemorySpace targetSpace = space-containing-id;
if not-found-in-any-space then targetSpace = currentSpace;
targetSpace[id] = value;
}
After decoding the assignment statement and triggering an action, the parser continues on to the next statement. This is just like a physical processor moving onto the next machine instruction.
Beyond simple statements like assignments, a syntax-directed interpreter runs into two complexities. First, it sometimes has to parse statements without triggering interpreter actions. Second, the return statement implementation has two call stacks to worry about: that of the interpreted language and that of the implementation language.
Let's look at why we'd ever want to parse without executing. When the interpreter sees a function definition, it shouldn't execute the statements in the function body. It should only execute the statements when someone calls that function. We need to distinguish between deferred mode and immediate mode. During function definition, the interpreter processes instructions in deferred mode. (It parses but does not trigger actions except the function definition action.) During a function call, the interpreter processes statements in immediate mode (parse and trigger actions). This dual mode operation is a bit of a problem because we have one parser and actions strewn all over. To turn actions on and off, we can pass in a boolean parameter, say, defer to the parser method responsible for executing statement lists. If defer is true, that method should turn off action execution.
This problem also appears when processing if and while statements. When a condition is false in an if statement, the interpreter should skip the first clause statement end execute the ``else'' clause. For example, the following if condition is false so it should print yep not nope.
if false print "nope" else print "yep" # prints "yep"
Because the then clause could include a nested if statement, we can't simply scan ahead looking for else. We have to parse the ``then'' clause. The solution is to skip (parse but don't execute) both clauses and then decide in the interpreter which we need to execute. The interpreter can test the condition result and then call, say, an exec() method to execute the code block starting at the appropriate address (token index). exec() must rewind the input stream to the start of either clause, execute it, and pop back to the end of the if statement. As before, we can use a defer parameter to switch interpreter actions on and off in the parser methods.
The second complication involves getting the return statement to pop back out of multiple method calls in our implementation. The return statement should make the interpreter return to the statement following the calling statement. Clearly, though, we can't map return in the interpreted language to return in our implementation language:
void returnstat() { return; } // oops; improper return mechanism
To call a function, we invoke interpreter method call(). call() computes the start address of the function's body (statement list) and executes the statement list via exec(). Ultimately, the parser will trigger returnstat(). The problem is that we need to unroll the returnstat() and exec() action methods all the way back the call() method. That's exactly what exceptions do. So, all we have to do is wrap the execution of the function body in a try-catch:
void call(String name, List<Object> argValues) {
<literal:ldots/>
try { exec(<literal:elide>start-of-function-body</literal:elide>); }
catch (ReturnException re) { ; } // returnstat exception comes here
}
Method returnstat() throws a ReturnException (or whatever you want to call it). If there is a return value, we can store it in the exception object. This mechanism isn't slow if we share the same exception object. Only creating exceptions is expensive; throwing them is no big deal. So no matter how deep our implementation's method call stack is, returnstat() will always get us back to the statement following the function body execution.
At this point, we know how the processor triggers actions to implement instructions. Some of those instructions provide control-flow and some load and store values from and to memory. There are also two weird instructions that define function and struct symbols. Because this pattern doesn't have a pre-execution pass over the input, we have to define symbols at runtime. The next section describes the instructions associated with creating symbols and explains how assignments create global and local variables.
Storing symbols in memory spaces
Because of Pie's Python-like semantics, we can get away without a scope tree for this pattern. All we need are symbol table objects for struct and function definitions. And, we'll store those symbols in the memory spaces as name-symbol pairs just like variables. So, memory spaces do double duty as scopes as well memory storage dictionaries.
As a syntax-directed interpreter executes a program, it maintains the notion of the ``current space.''. The current space is similar to the current scope. The difference is that the current scope moves in and out of function bodies as a language application reads the source code from top to bottom. The current space moves in and out of functions per their function call order dictated by the program logic (not the function's physical order in the file).
The current space starts out as the global space. Upon each function call, the interpreter creates a new function memory space (FunctionSpace) and pushes it onto the stack. That space becomes the new current space. All definitions happen in the current space just as they did during static analysis in the current scope.
Before looking at functions and struct}}s, let's look at variable creation. Upon assignment such as {{x=1, we try to resolve x. In this pattern, to resolve means to look for it in the space on the top of stack or global space (if not on stack). If x isn't defined, we created a new variable in the current space. If the assignment is outside of a function, the interpreter creates a global variable. If the assignment is within a function, it creates a local variable. We also try to resolve x references not on the left side of an assignment. If it's not defined anywhere, though, it's an error.
Variables are just name-value pairs; we don't have a formal symbol table object since we don't need one. (There's nothing other than a value to associate with a variable.) Functions and {{struct}}s, on the other hand, require formal symbol objects (from Section ``Symbol table for data aggregates'' in Language Implementation Patterns).
To define a function, we create a FunctionSymbol object and record the formal parameter list and the token index of its body. Then, we map the function's name to that symbol in the current space as if it were a variable.
To call a function, we look up the method name and get the list of formal parameters. Before jumping to the function body, we map the formal parameter names (in order) to the the parameter values found in the call expression.
To define a struct, we create a StructSymbol object and record the list of fields. Then we map the name to that symbol in the current space just like we did for functions and variables. By storing struct definitions in the current space, Pie allows local struct definitions as shown in the following program (localstruct.pie).
struct User { name, password } # define global struct
def f(): # define f
struct User { x, y } # hides global User def
u = new User # create new User instance, put in local u
print u # prints "{x=null, y=null}"
. # end body of f
print new User # prints "{name=null, password=null}"
f() # call f
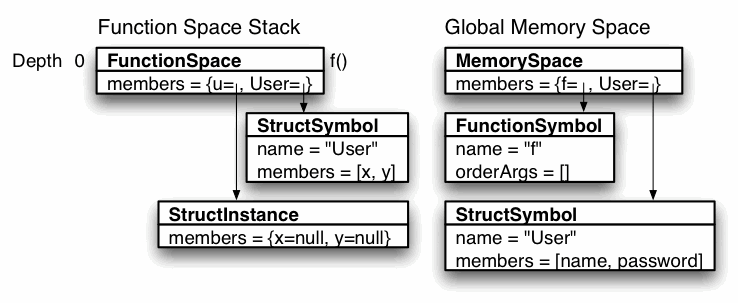
The following figure illustrates how the interpreter stores symbols and variables together in the same space. Inside f(), User resolves to the local definition. Outside of the function, User resolves to the definition in the global space. The assignment to u in f() creates a local variable, defining it in the FunctionSpace object's members list.
That's basically it. A syntax-directed interpreter is little more than a parser that triggers action methods. These methods alter control-flow, shuffle data around in memory, and define symbols. The next section provides a complete implementation that fills in any remaining details for this pattern.
Implementation
To implement a syntax-directed interpreter we're going to build a grammar (Pie.g) that parses Pie code and triggers support methods in an Interpreter object. We'll construct a partial symbol table during execution to hold function and struct symbols. Our main program lives in InterPie and calls interp() on a new Interpreter. Let's start by looking at the basic infrastructure objects for dealing with symbols and memory spaces. Then, we can jump into the grammar that drives everything.
Infrastructure objects for data and symbols
Our symbol table consists of FunctionSymbol and StructSymbol objects from Section ``Symbol table for data aggregates'' in Language Implementation Patterns. Since there is no scope tree, we don't interconnect these objects at all. We only need them to track parameter and field lists. Instead of a scope tree, Pie has a very simple semantic context. Either a symbol is on the top of the function call stack or it's in the global space. Function symbols, struct symbols, and variables all go into memory spaces.
Variables, parameters, and fields live in one of several kinds of MemorySpace objects. Globals go into a plain MemorySpace. Local variables and parameters go into FunctionSpace objects pushed on the stack upon each Pie function call. Each new expression creates a StructInstance to hold fields.
An Interpreter object wraps up all those memory spaces (and holds the code memory and parser reference):
MemorySpace globals = new MemorySpace("globals"); // global memory
MemorySpace currentSpace = globals;
Stack<FunctionSpace> stack = new Stack<FunctionSpace>(); // call stack
TokenRewriteStream tokens; // token buffer represents the code memory
PieLexer lex; // lexer/parser are part of the processor
PieParser parser;
The meat of our interpreter lies in the parser that triggers a bunch of small action methods (such as ifstat() and call()) housed within Interpreter. Let's explore the ANTLR grammar in Pie.g to see how it collaborates with the action methods.
Grammar and action methods
Pie programs consist of a sequence of function definitions and statements. To allow struct definitions within functions, we'll consider them statements. Here's our top-level rule:
program : ( functionDefinition[false] | statement[false] )+ EOF ;
Each rule in our grammar below program has a defer execution mode parameter that indicates whether the rule should execute actions. At the highest level we pass in defer as false because we want immediate not deferred mode. We want to execute statements right away and also to define symbols for functions right away:
functionDefinition[boolean defer]
: 'def' name=ID '(' (args+=ID (',' args+=ID)*)? ')' slist[true]
{if (!defer) interp.def($name.text, $args, $slist.start);}
;
Notice that functionDefinition passes true to the statement list rule (slist) so that it doesn't execute the body statements. The args+=ID expressions track all ID tokens in a list. The def() interpreter method needs three things: the name, the formal list of parameters ($args), and the body's starting token index ($slist.start):
public void def(String name, List<Token> args, Token codeStart) {
Symbol f = new FunctionSymbol(name, args, codeStart);
currentSpace.define(f);
}
struct definitions look similar. The rule tracks a list of field names and passes them to the aggr() interpreter method.
structDefinition[boolean defer]
: 'struct' name=ID '{' fields+=ID (',' fields+=ID)* '}' NL
{if (!defer) interp.aggr($name.text, $fields);}
;
Turning to the executable statements now, let's look at assignment. We can either assign to a simple variable or to a field of a struct:
assign[boolean defer]
: ID '=' expr[defer] NL // E.g., "a = 3"
{if (!defer) interp.assign($ID.text, $expr.value);}
| structscope[defer] '.' ID '=' expr[defer] NL // E.g., "a.b.x = 3"
{if (!defer) interp.fieldassign($structscope.value, $ID, $expr.value);}
;
The rule matches the right hand side of an assignment with expr, which matches and computes the value of an expression. $expr.value is the return value of expr. To determine the struct memory space for a field access like a.b.x, we ask structscope to match a.b and return the appropriate struct instance (via $structscope.value):
/** return struct scope to left of last '.'; a.b in a.b.c, for example */
structscope[boolean defer] returns [StructInstance value]
: ids+=ID ('.' ids+=ID)*
{if (!defer) $value = interp.getStructSpace($ids);}
;
The expression rules match subexpressions and return their computed values. The simplest subexpressions are identifiers and literals like integers:
atom[boolean defer] returns [Object value]
: INT {if (!defer) $value = $INT.int;} // return int value
| ID {if (!defer) $value = interp.load($ID);} // look up value
...
The load() interpreter method eventually calls the following method to load a value.
/** Find id in current semantic context */
public Object load(String id) {
MemorySpace s = getSpaceWithSymbol(id);
if ( s!=null ) return s.get(id);
return null;
}
That method merely does a dictionary lookup once getSpaceWithSymbol() finds the memory space holding that symbol:
/** Return scope holding id's value; current func space or global. */
public MemorySpace getSpaceWithSymbol(String id) {
if ( stack.size()>0 && stack.peek().get(id)!=null ) { // in top stack?
return stack.peek();
}
if ( globals.get(id)!=null ) return globals; // in globals?
return null; // nowhere
}
To add or subtract values, we match the appropriate subexpression and then call add() or sub() with the appropriate operands.
addexpr[boolean defer] returns [Object value]
: a=mulexpr[defer] {if (!defer) $value=$a.value;}
( '+' b=mulexpr[defer]
{if (!defer) $value=interp.add($a.value, $b.value);}
| '-' b=mulexpr[defer]
{if (!defer) $value=interp.sub($a.value, $b.value);}
)*
;
Each time through the (...)* loop, the action sets the $value return value for addexpr. This should give you enough of a head start so that you can read the rest of the expression rules in Pie.g on your own.
And now for the tricky stuff. The if statement might start out in immediate mode but has to flip to deferred mode for its condition expression and statement clauses. No matter what, we have to parse the entire statement even if we don't execute the then clause. All rule ifstat does is pass the starting token index of the various subclauses to ifstat() in the interpreter:
ifstat[boolean defer]
: 'if' expr[true] c=slist[true] ('else' el=slist[true])?
{if (!defer) interp.ifstat($expr.start, $c.start, $el.start);}
;
It's up to ifstat() then to evaluate the condition and decide whether to execute the then clause (or else clause if present):
public void ifstat(Token condStart, Token codeStart, Token elseCodeStart) {
// evaluate the condition expression
Boolean b = (Boolean)exec("expr", condStart.getTokenIndex());
if ( b ) { // if true, do the then clause
exec("slist", codeStart.getTokenIndex());
}
// do else clause if !b and else exists
else if ( elseCodeStart!=null ) {
exec("slist", elseCodeStart.getTokenIndex());
}
}
The implementation of a while loop is the same except that it executes the body while the condition expression is true.
Both if and while implementations rely on an important method called exec(). exec() knows how to start parsing at a particular code location (token index) using a particular grammar rule:
public Object exec(String rule, int tokenIndex) {
Object rv = null;
try {
int oldPosition = parser.input.index(); // save current location
parser.input.seek(tokenIndex); // seek to place to start execution
try { // which rule are we executing?
if ( rule.equals("expr") ) { rv = parser.expr(false).value; }
else if ( rule.equals("slist") ) { parser.slist(false); }
else listener.error("error: can't start at "+rule);
}
finally { parser.input.seek(oldPosition); }// restore location
}
catch (Exception e) {
listener.error("can't exec code @ index "+tokenIndex, e);
}
return rv;
}
exec() saves and restores the parser's current location before going off to execute another code chunk. After calling exec(), the parsing location will be as it was before calling exec().
The only other action method that needs exec() is call(). To call a Pie function, we have to make sure the function exists and that there is no mismatch in the number of parameters. The number of actual parameters passed to the function has to be the same as in the formal parameter list. Then we assign the actual parameters to the formal parameter names in a newly created function memory space (FunctionSpace), in the order given by the formal parameters. At that point, we're ready to execute the body of the target function with exec(). As we discussed in the introductory material for this chapter, returnstat() uses an exception to unroll the Java stack back to the call to exec() in call(). Here is the implementation of call():
// Interpreter.java
public Object call(String name, List<Object> args) {
FunctionSymbol f = (FunctionSymbol)load(name); // find function
if ( f==null ) { listener.error("no function "+name); return null; }
FunctionSpace fspace = new FunctionSpace(f);
MemorySpace saveSpace = currentSpace;
currentSpace = fspace;
if ( f.formalArgs==null && args.size()>0 || // args compatible?
f.formalArgs!=null && f.formalArgs.size()!=args.size() ) {
listener.error("function "+f.name+" argument list mismatch");
return null;
}
// define parameters according to order in formalArgs
for (int i = 0; f.formalArgs!=null && i < f.formalArgs.size(); i++) {
Token a = (Token)f.formalArgs.get(i); // get formal name
fspace.put(a.getText(), args.get(i)); // set name=arg-value
}
Object result = null;
stack.push(fspace); // Push parameter/local space for this call
try { exec("slist", f.firstTokenOfBlock.getTokenIndex()); }
catch (ReturnValue rv) { result = rv.value; } // trap return value
stack.pop(); // toss out local and parameter space
currentSpace = saveSpace;
return result;
}
Let's run some sample Pie programs through our interpreter.
Building and running the interpreter
To build this interpreter, run ANTLR on Pie.g and then compile all of the Java files in the directory:
$ java org.antlr.Tool Pie.g
warning(200): Pie.g:51:39: Decision can match input such as "'else'"
using multiple alternatives: 1, 2
As a result, alternative(s) 2 were disabled for that input
$ javac *.java
$
You can ignore the warning message from ANTLR; it's the standard if-then-else ambiguity. (See Subsection Nondeterministic Decisions of Section 11.5 in The Definitive ANTLR Reference for more details.) Let's test the main program, InterPie, on a factorial program:
$ cat factorial.pie
def fact(n):
if n < 2 return 1
return n * fact(n-1)
.
print fact(10)
$ java InterPie factorial.pie
3628800
$
Here's another test that exercises struct's:
$ cat struct.pie
struct User { name, password }
u = new User
u.name = "parrt"
print "Login: "+u.name
print u
$ java InterPie struct.pie
Login: parrt
{name=parrt, password=null}
$
There are several other test files in the source directory that demonstrate this implementation's functionality (including error handling).
This interpreter isn't the simplest one around. Because we're executing source code not machine code, we have to deal with: immediate versus deferred mode execution, exceptions to implement return, and the combined notion of scopes and memory spaces. The more we process code towards machine code, the simpler the actual interpreter component (and the more it looks like a CPU emulator).
Don't forget that the source is available as an attachment to this page.