...
The DFA that predicts alternatives of rule stat looks complicated, but it's really just trying to see past the letters to the characters that follow. LL(*) handles this with no problem but LL(k), with its fixed k lookahead, couldn't predict alternatives. Here is the DFA:

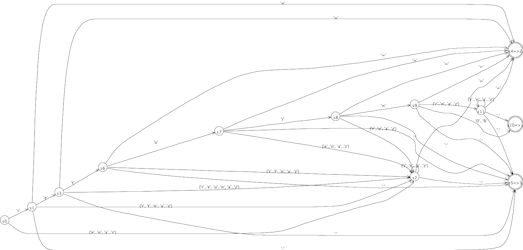
The trick to making this work is to create a stream of tokens that are really characters. The problem is that, since were making a parser grammar not a lexer grammar, ANTLR thinks that the character 'a' is really some random token type instead of the ASCII code. Using the tokenNames array in the generated parser, the following class figures out what the right token type is for each input character.
| Code Block | ||
|---|---|---|
| ||
import org.antlr.runtime.CharStream;
import org.antlr.runtime.CommonToken;
import org.antlr.runtime.Token;
import org.antlr.runtime.TokenSource;
import org.antlr.tool.Grammar;
import java.util.LinkedHashMap;
import java.util.Map;
public class CharsAsTokens implements TokenSource {
CharStream input;
String[] tokenNames;
int line=1;
int charPosInLine;
Map<Integer, Integer> charToTokenType = new LinkedHashMap<Integer, Integer>();
public CharsAsTokens(CharStream input, String[] tokenNames) {
this.input = input;
this.tokenNames = tokenNames;
int ttype = 0;
for (String tname : tokenNames) {
if ( tname.charAt(0)=='\'' ) {
charToTokenType.put(Grammar.getCharValueFromGrammarCharLiteral(tname), ttype);
}
ttype++;
}
System.out.println(charToTokenType);
}
public Token nextToken() {
Token t = null;
consumeUnknown();
int c = input.LA(1);
int i = input.index();
if ( c == CharStream.EOF ) {
t = Token.EOF_TOKEN;
}
else {
Integer ttypeI = charToTokenType.get(c);
t = new CommonToken(input, ttypeI, Token.DEFAULT_CHANNEL, i, i);
}
t.setLine(line);
t.setCharPositionInLine(charPosInLine);
consume();
return t;
}
protected void consumeUnknown() {
int c = input.LA(1);
Integer ttypeI = charToTokenType.get(c);
while ( ttypeI==null && c != CharStream.EOF ) {
System.err.println("no token type for char '"+(char)c+"'");
c = consume();
ttypeI = charToTokenType.get(c);
}
}
protected int consume() {
int c = input.LA(1);
input.consume();
if ( c == '\n' ) { charPosInLine = 0; line++; }
charPosInLine++;
return input.LA(1);
}
public String getSourceName() {
return null;
}
}
|
To try this out, the following test rig works. The only difference is that we are using a weird kind of lexer:
| Code Block | ||
|---|---|---|
| ||
import org.antlr.runtime.*;
public class Test {
public static void main(String[] args) throws Exception {
CharStream in = null;
if ( args.length>0 ) in = new ANTLRFileStream(args[0]);
else in = new ANTLRInputStream(System.in);
CharsAsTokens fauxLexer = new CharsAsTokens(in, T.tokenNames);
CommonTokenStream tokens = new CommonTokenStream(fauxLexer);
tokens.fill();
System.out.println(tokens.getTokens());
T parser = new T(tokens);
parser.prog();
}
}
|
For input:
| No Format | ||
|---|---|---|
| ||
return 23; a = b; |
We get the following output (the hash table printed out first is the mapping of ASCII code to token type). we ignore any input character for which the grammar has no reference, such as newline whitespace. Finally, I print out the token list before parsing and then, generating with the trace option, we see the entry and exit rule events during the parse:
| No Format |
|---|
$ java org.antlr.Tool T.g
$ javac *.java
$ java Test input
{48=4, 49=5, 50=6, 51=7, 52=8, 53=9, 54=10, 55=11, 56=12, 57=13, 59=14, 61=15, 97=16, 98=17, 99=18, 100=19, 101=20, 110=21, 114=22, 116=23, 117=24}
no token type for char ' '
no token type for char '
'
no token type for char ' '
no token type for char ' '
no token type for char '
[[@0,0:0='r',<22>,1:0], [@1,1:1='e',<20>,1:1], [@2,2:2='t',<23>,1:2], [@3,3:3='u',<24>,1:3], [@4,4:4='r',<22>,1:4], [@5,5:5='n',<21>,1:5], [@6,7:7='2',<6>,1:7], [@7,8:8='3',<7>,1:8], [@8,9:9=';',<14>,1:9], [@9,11:11='a',<16>,2:1], [@10,13:13='=',<15>,2:3], [@11,15:15='b',<17>,2:5], [@12,16:16=';',<14>,2:6], [@13,0:0='<no text>',<-1>,3:1]]
enter prog [@0,0:0='r',<22>,1:0]
'
enter stat [@0,0:0='r',<22>,1:0]
enter kreturn [@0,0:0='r',<22>,1:0]
exit kreturn [@6,7:7='2',<6>,1:7]
enter e [@6,7:7='2',<6>,1:7]
enter integer [@6,7:7='2',<6>,1:7]
enter digit [@6,7:7='2',<6>,1:7]
exit digit [@7,8:8='3',<7>,1:8]
enter digit [@7,8:8='3',<7>,1:8]
exit digit [@8,9:9=';',<14>,1:9]
exit integer [@8,9:9=';',<14>,1:9]
exit e [@8,9:9=';',<14>,1:9]
exit stat [@9,11:11='a',<16>,2:1]
enter stat [@9,11:11='a',<16>,2:1]
enter id [@9,11:11='a',<16>,2:1]
enter letter [@9,11:11='a',<16>,2:1]
exit letter [@10,13:13='=',<15>,2:3]
exit id [@10,13:13='=',<15>,2:3]
enter e [@11,15:15='b',<17>,2:5]
enter id [@11,15:15='b',<17>,2:5]
enter letter [@11,15:15='b',<17>,2:5]
exit letter [@12,16:16=';',<14>,2:6]
exit id [@12,16:16=';',<14>,2:6]
exit e [@12,16:16=';',<14>,2:6]
exit stat [@13,0:0='<no text>',<-1>,3:1]
exit prog [@14,0:0='<no text>',<-1>,3:2]
|