ramblings about design as stream of consciousness
I built a quick mockup with NetBeans just so that I have all of the Windows in front of me with a couple of faked images. The basic design is easy because NetBeans allows us to move windows around as we want. I happen to lay the Windows out like this:
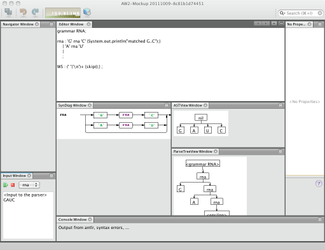
(Sam already has the navigator and the editor Windows filled in, but I was too lazy to incorporate.)
Every window has content, publishes events, and listens for events. For example the navigator window, listens for publication events from the editor window saying "heh I have a grammar". It then displays the list of lexer and parser rules. It, in turn, publishes selection events that the other Windows can listen in on. The editor window moves the cursor position to the selected rule. The properties window might say something about that rule. The syntax diagram window shows the syntax diagram for the selected rule.
Keeping Windows in sync
Lots of the Windows published selection events: navigator window, editor window, syntax diagram window, AST window, and parse tree window. They also listen for the selection events so that all of those Windows can stay in sync. If you select a rule in the navigator, perhaps it selects all rule references in the parse tree.
There's a difference between selecting a rule in the navigator and selecting a specific rule or token reference in a tree. The tree views are representations of the tokens in the input window and how they are parsed. So the trees and the input windows need to be kept in sync and they also published selection events to highlight the appropriate elements in the grammar.
The only selection event published by the editor window is the current rule. I guess that means that as you move the cursor through the editor, the rule in the navigator should also be selected.
Debugger
There is no "debugger" per se. We simply run or interpret the grammar and get a parse tree and, if running with output=AST, we also get an AST. Once we have recorded the entire parse, we may want to walk back through it. Technically, there's no reason to actually step through anything because you can see the entire parse. That said, I think it would be useful to be able to single step by input token or even position within the syntax diagram. This information would be available via the parse log generated during interpretation or parser execution. I have no idea what that log will look like but it will clearly need to include:
- grammar (as a reference to the filename or the actual file contents)
- the input
- the parse tree. this would have parameters and local variable values if it's being run not interpreted
- the AST if this thing is being run not interpreted
By selecting elements in the AST or parse tree, the properties window can show information about that node. For example, the parse tree node property sheet which show whatever labels, parameters, etc... were computed. We could even show via reflection the elements of the AST nodes very much like a full Java debugger. At some point, we might actually use the debugger components of the NetBeans platform to make this more "live"
I do not intend to expose the underlying augmented transition network (ATN) to the user. Any kind of stepping should be done by walking the syntax diagram (which is really the dual of the ATN anyway).
Internal models
ANTLR v4 parses grammars into GrammarAST heterogeneous ASTs and then constructs ATNs from those ASTs and finally generates code from the ASTs. I can't get away from building some kind of internal data structure and we already have the GrammarAST so let's keep it. I also need the ATN so that I can generate it into the output (and also use it for the interpreter). Can't get away without that either. Okay so we are stuck with both the tree and an ATN model of the input.
What model or models do we use for the navigator tree and the syntax diagram. The Nodes API needs nodes objects for the navigation window. These will be wrappers on some other internal model object I guess.
The syntax diagram prototype that Colin is working on uses its own model of the grammar rule such as Rule, Alternative, Element, token ref, rule ref, loop, etc... That is probably fine for experimenting, but even as we moved to a prototype it seems like we should come up with an internal model needed by ANTLRWorks that we can share.
One option is to have Colin walk the AST manually or with a tree grammar to compute size and position of the syntax diagram subcomponents. I could also augment the GrammarAST class hierarchy to beogrammer friendly and include a visitor dispatch mechanism. The current hierarchy is actually almost like a simple input model like what Colin is using now:
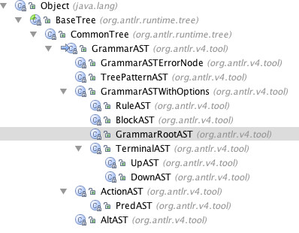
It looks like I would have to add AST nodes for some of the other rule elements such as * and + loops, but that is no big deal. Then, instead of simple getChildren() I could add specific methods such as AltAST.getRuleElements() etc... This would make it much easier to use by other people.
What do the navigator nodes wrap? The top level nodes are just lexer and parser so they can wrap just a string and pointer to the underlying v4 Grammar object. The second level nodes are the rule names. Perhaps they should wrap the Rule objects created by v4. These Rule objects have a pointer to the AST which knows where it came from in the text of the grammar. That would allow us to navigate, moving the cursor in the editor window. Actually, perhaps the navigator should simply wrap the (not yet implemented) RuleAST nodes.
Yep, as I write this, it seems like the right answer is to beef up the AST class hierarchy so that it's more programmer friendly. If I did this again, I would go the parse tree but that would require some pretty significant changes through the code generator and all the other systems. Maybe I should simply have ANTLR created a parse tree as well as an AST using some kind of option. That parse tree would make it harder to walk, however, at least manually.
Uniquely identifying window elements
We need a way to uniquely identify the rule elements such as a token references and rule references within a rule. We also need to map that unique identifier to a node in the syntax diagram. Nodes in the parse tree and AST must map back to these unique identifiers so that we can highlight elements in the grammar. Basically we need to publish "location 46" and have at least three Windows know which element to highlight: the parse tree, the AST, and the syntax diagram. The navigator should also highlight the rule that contains location 46, whatever that element is.
We can't use the ATN state number because AW has no reason to create the ATN unless it's planning on doing interpretation of the grammar. It would probably create this on-demand. Probably would be better to use something like the unique identifier mechanism I had in ANTLR v3:
public class GrammarAST extends CommonTree {
static int count = 0;
public int ID = ++count; // unique identifier per AST node
...
}
As the syntax diagram created nodes from AST nodes, it would record a reference back to the AST from which it was derived. Selecting this syntax diagram node later, would publish the unique identifier of the grammar AST node.
The interpreter feeds off of the ATN, whose states all know from which GrammarAST node they were derived (or could be made to track). As it created parse tree elements, it could track the appropriate unique identifier pulled from the GrammarAST nodes. Uh, wait. The ATN state Transition objects are the things that correspond to grammar elements. As it transitions, the interp would record the GrammarAST identifier.
If we actually execute a parser, we have a problem. At parse time, we always know where we are in the ATN, but we have no idea how that corresponds to elements in the original grammar. I guess I could create a mapping as part of the ATN I generate in the parser file. The mapping would convert ATN transitions to the unique identifiers in the GrammarAST nodes. They are like pointers that would transcend Java VM executions. As long as we have the same grammar, the GrammarAST unique identifiers would be the same. That assumes of course that we have a deterministic process for creating the unique identifiers, which we would by using the above counter.
Such a map would be extremely useful for syntax error reporting during development. Given a state within the ATNState, the parser could immediately identify where exactly in the grammar the input fail to match. We could even pop up ANTLRWorks and show you exactly where in the grammar the parse was.
As part of a parse log, we could keep the exact list of GrammarAST unique identifiers that we pass through. At the moment, I track the ATN state number, but instead I think I should track the transition objects' GrammarAST unique identifiers. This way, ANTLRWorks could single step through the syntax diagrams and grammar to show you the trace.
We also want to be able to click on an input symbol and have ANTLRWorks highlight where the grammar and syntax diagram that token was matched. I guess we need a list of GrammarAST unique identifiers that correspond to the input symbols. Four 100 input symbols, we would have a list of 100 unique identifiers. to single step through the input would then be easy. So, we would have both single step by input as well as single step through the grammar as a result of a parse. tasty.
Action items
I guess I just need to do this:
- Beef up GrammarAST, adding more types, getters
- Add unique ID to GrammarAST
- Add GrammarAST ptr in Transition objects
- Generate information in the generated code that maps ATN transitions to GrammarAST unique identifiers.
- Alter the trace ATN mechanism so that it tracks ATN transitions not the states
- Create a mechanism to record the unique identifier for each input symbol matched during a parse.
I just finished attending a three day workshop on developing standalone GUI applications with this awesome Java applications framework that you've never heard of. Actually, that's not true. You've heard of it but thought it was an IDE--NetBeans. Unfortunately, the amazing applications framework has been hitched to the NetBeans IDE wagon which, for better or worse, has much less market share than eclipse. (I know how NetBeans users feel because I use Intellij, both of which are swamped by eclipse users.)
I've built a number of applications with Swing, but Swing is just so primitive. Every GUI I build has to reimplement all of the usual application lifecycle and menu stuff. No one uses Swing partly for this reason. Unfortunately, I understand that Sun now Oracle uses the lack of users as a justification to dump it. If you're old enough to remember the birth of Java, you'll recall that all the excitement about it came down to one word: Applets. That is pretty funny because of course no one uses it for applets. Why not? AWT, the windowing library at the time, was terrible. Swing was meant to fix this and, years later after they fixed the speed issues, it's actually okay (though it still pretty low level). The problem was and is that it's not an application framework and we build applications not widgets.
Personally, I greatly prefer using a GUI app sitting on my machine rather than a web app (pretty funny since I'm teaching a graduate course in web systems and algorithms this semester). Anybody who's tried to use google's spreadsheet or document editor online knows what I'm talking about. Anybody try using a web-based development environment? Surely, were not going to dump our IDEs and start typing into web browsers. As Cay Horstmann's JavaOne blog points out
But my feeling is that there is a continued need for the desktop. Information consumers won't care, but information producers do. Someone needs to write code, write books, do art layout, run complex calculations. The desktop has been pretty well optimized for that. Java and JavaFX have the chance to dominate that market while everyone else chases consumer tablets.
There are lots of people still building GUIs, but most of these are internally used by corporations and government organizations that aren't necessarily going to blog about their competitive advantage (e.g., trading software) or give out their software. You can check out some sample applications built with the NetBeans Platform. I notice that lots of those organizations still building GUIs are flush with cash: banks, the military, the government, ...
I understand that all the excitement is about the web and mobile applications. I'm sure if I were 22 again, that's what I would be excited about. Building the very large jGuru.com server 10 years ago pretty much knocked the excitement out of it for me. Next.
Anyway, there also sometimes very good reasons not to build web-based applications. Aside from the difficulty of building rich clients beyond some gee-whiz JavaScript, the first thing I have to do with a web application is come up with a Web server somewhere (and pay for it plus bandwidth). This exposes me to security issues and I have to figure out how to get two computers to communicate with protocols instead of using method calls. It's just one more thing to break and I need to have an active network connection to use my application.
I'm really glad people are out there building cool mobile applications and web applications, but please don't deny desktop applications have their place and please make it easy to build GUIs myself. So here is what I want: Oracle should fork off the applications framework, clean it up, and ship it as a separate product. The NetBeans IDE is already just an application that sits on top of this framework. Come on, folks. Let's put some effort into this application platform, to be named later. ![]()
In closing, let me thank Geertjan Wielenga for giving the NetBeans workshop (an excellent instructor and nice guy) and Andreas Stefik for helping explain more about the NetBeans Platform via his SodBeans IDE for the visually impaired.
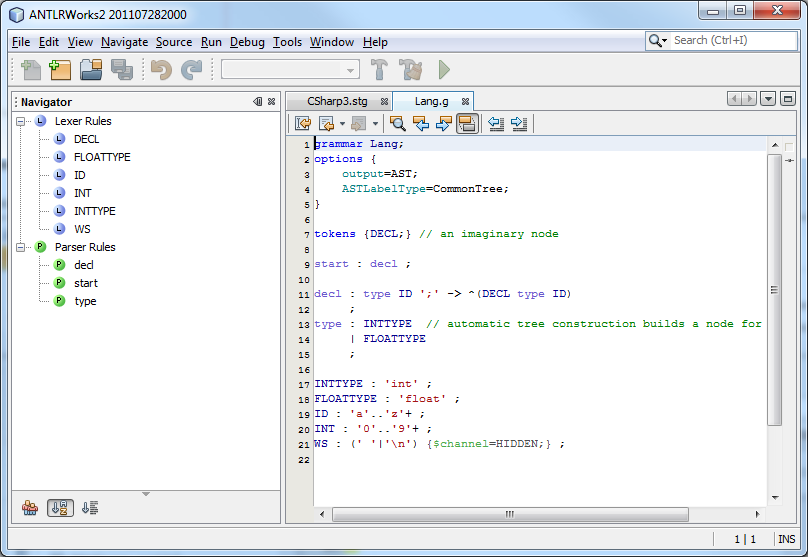
Sam Harwell, Colin Bean, Udo Borkowski, Shaoting Cai and I are using NetBeans Platform to build a new ANTLRWorks grammar IDE. More on that later. Here are a few snapshots of the editor for grammars and StringTemplates that Sam got working within a few days: