v4 code generation
- TerenceP
ANTLR v3's code generator was a huge improvement over v2's. v2 totally entangled code generation logic and print statements. to make a new target, you copied the entire undignified blob and tweaked the print statements. Changes to the translation logic required duplicate changes across all targets. ANTLR v3 has a single code generator object and, besides a little bit of code for translating character literals and so on, targets are exclusively specified with a set of templates.
That's the good news. The bad news is, as I look over the code, that the code generation code is pretty gross and it's not easy to figure out which part of the translation happens when. Moreover, there is a proliferation of templates. For example, the humble token reference has many different variants, depending on whether we are generating trees, whether it has a label, and so on. I spoke with Jim Idle on the phone today and he suggested that we have one template to handle token references and then use IF statements within the template like "if AST", "if DBG", "if label" etc. I'll have to see how that looks. I'm a little bit uncomfortable with the concept of a bunch of conditionals as it might look like too much business logic in the templates. At the same time, I want to give as much freedom as possible to the target developers so they can generate code that's appropriate or efficient for the target.
What we need to build the new code generator
First, lets come up with a list of the major components:
- grammar AST walker that creates templates and cobbles them together into one large output template
- Cyclic DFA generator
- Acyclic DFA generator; handles purely LL(k) decisions
- NFA bytecode generator for lexers
- Action translator for embedded expressions like $x.y and $text
To generate code, we need the following information and data structures:
- The grammar in the form of an AST
- Rule and Grammar objects that can answer questions about:
- options
- rule parameters/return values
- rule exception specifications
- scopes
- actions such as @members, @init
- Prediction DFA for any decision in a parser or tree parser (lexers use an NFA VM)
- Use-def information about labels and tree construction references; we don't want to generate AST tracking information for elements not used in tree construction rewrite rules
Things to keep in mind:
- try to reduce the number of templates
- try to reduce the number of attributes being sent in, in favor of appropriate objects like Rule and Grammar objects. The v3 code generator is rife with "set attribute" code.
What should the code generator look like?
Let's start from the result and work backwards. Let's build sample (working) parser snippets for the various situations we'll encounter.
LL(1) decision block with/without predicates
We should shoot for a simple switch. If the DFA is equivalent to an LL(1) predictor, we collect all branches that lead to a particular accept state and put them into one case list:
switch ( input.LA(1) ) {
cases for alt1:
code to match alt1;
break;
cases for alt2:
code to match alt2;
break;
...
cases for altN:
code to match altN;
break;
default :
report error and recover
}
LL(1) EBNF constructs
(...)?
If only one alternative, it's special:
if ( input.LA(1) in tokens for alt1 ) {
code to match alt1;
}
else report error and recover
Hmm...what about the error sync? seems like we might want that error detection first:
if ( input.LA(1) not valid at this point ) report error and recover
// we might have consumed an extraneous token; try the subrule now
if ( input.LA(1) in tokens for alt1 ) {
code to match alt1;
}
else report error and recover
(...)*
Single alt case:
sync
while ( input.LA(1) in tokens for alt1 ) {
code to match alt1;
sync
}
>1 alt case:
sync
loop:
while ( true ) {
switch ( input.LA(1) ) {
cases for alt1:
code to match alt1;
break;
cases for alt2:
code to match alt2;
break;
...
cases for altN:
code to match altN;
break;
default :
if ( input.LA(1) in FOLLOW ) break loop;
report error and recover
}
}
(...)+
Because of sync before loop, (...)+ is same as (...)*. The sync guarantees that we scarf until we see something that starts the (...)+.
Linear approximate LL(k) decision block (without predicates)
We only do k=2 I think. Do we need anymore?
if ( LA(1) in alt1[1] && LA(1) in alt1[2] ) {
code for alt1
}
else if ( LA(1) in alt2[1] && LA(1) in alt2[2] ) {
code for alt2
}
...
else if ( LA(1) in altN[1] && LA(1) in altN[2] ) {
code for altN
}
For (...)* loop:
sync
while (true) {
if ( LA(1) in alt1[1] && LA(1) in alt1[2] && ... ) {
code for alt1
}
else if ( LA(1) in alt2[1] && LA(1) in alt2[2] && ... ) {
code for alt2
}
...
else if ( LA(1) in altN[1] && LA(1) in altN[2] && ... ) {
code for altN
}
else {
if ( input.LA(1) in FOLLOW ) break loop;
report error and recover
}
}
For (...)+ loop:
int cnt=0;
loop:
while (true) {
if ( LA(1) in alt1[1] && LA(1) in alt1[2] && ... ) {
code for alt1
}
else if ( LA(1) in alt2[1] && LA(1) in alt2[2] && ... ) {
code for alt2
}
...
else if ( LA(1) in altN[1] && LA(1) in altN[2] && ... ) {
code for altN
}
else {
if ( cnt>0 && input.LA(1) in FOLLOW ) break loop;
if ( cnt==0 && input.LA(1) in FOLLOW ) {
report early exit
break loop;
}
report error and recover
}
cnt++;
}
LL(k) decision block with/without predicates
LL(k) EBNF constructs
Cyclic DFA LL(*) with/without predicates
Cyclic DFA LL(*) EBNF constructs
Backtracking option forces backtracking across all alts
Backtracking across only some of the alts
Crazy code gen idea #1
I'm mid thought on this, but I'm thinking of trying out something akin to an LLVM IR approach. i think of it as doing for source code gen what TWIG/BURG did for assembly generation.
Instead of sharing common code chunks between matchToken, matchTokenRoot, matchTokenLeaf, etc... with another template and instead of lots of template variants, let's try to identify all the common chunks among all templates and identify some common operations. Then, we make those operations instructions in an IR. For example, token ref T would become
match T
then t=T would become
t = LT(1) match T
T^ would be
label42 = LT(1) match T root label42
rule ref r would be
r()
and r[3,"hi"]
becomes
t1=3 t2="hi" call r, t1..t2
and x=r[34] becomes
t1=34 rv = call r x.a = rv.a ; assume r returns values a and b not single value x.b = rv.b
etc...
The target developer can combine the operations into x=r(34) or push args onto software stack (to avoid pred hoisting issues), etc...
I'm thinking of a typed IR like llvm where we have token, tree, string, int etc...
Once we have that, it divorces the grammar to code part, though not the surrounding class and set up stuff.
One could even imagine some symbol table manipulation instructions.
We could interpret this or translate to source code with 1-to-1 templates for these canonical operations. We could even go straight to LLVM IR from this ANTLR IR for some serious cranking. heh,that's an interesting idea.
The good thing about this is that it'd be a well defined interface (finally!) for target developers. We could ALMOST just ask developers to identify what assignment, call, hashtable lookup, WHILE, IF looks like in their language to get a basic target built pronto. Beyond that we'd need them to identify patterns in the IR to make it higher level. It'll be a balance between high level enough to make it easy to map to high level code but low level enough to make it easy to share common elements.
I don't think we want really low level like:
switch 2 c1, c2
c1:
...
jmp end
c2: ...
end:
Perhaps:
choose dfa1 [ match A ] [ match B ]
star dfa1 [
block dfa2 [...] [...] [...]
]
while dfa1 [ ... ]
loop
choose dfa1 [...] [...]
default [ breakif set1; error ]
( A | b )
switch {A} [match A] {FIRST(b)} [match B]
if LL(k): (a|b) where FIRST(a)==(A B C) choose [test A then B||C] [call a] []
( A | B )?
sync {...} # if !{FIRST|FOLLOW of (A|B)?} error
optional {A} [match A] {FIRST(b)} [match B] {FOLLOW} BYPASS
Canonical operations
- match token possibly with label
- invoke rule possibly with args, possibly with label
- test lookahead depth i for token
- test lookahead depth i for token set using repeated lookahead tests
- test lookahead depth i for token set using bitset or hash
- alt block testing LA(1)
- optional block testing LA(1)
- star block testing LA(1)
- plus block testing LA(1)
- alt block testing k>1
- alt block testing cyclic dfa
- ...
More random thoughts
Use objects to abstract away rule code gen with simple rule template. Let people indicate how to define a label etc... but keep logic of as much as possible in output model object. reduce how much smarts are in templates made by target folks. Perhaps 2 levels of templates?
code gen figures out kind of thing to gen but not at statement level. Code gen figures out sync for errors too. Create output object model; single class for MatchToken but it knows how to gen variants? Have different output object for tree and debug parts of matchtoken and ruleref etc...
Output object model should be somewhere between the input model and output language statements. For flexibility, we don't want to create WHILE and IF output model objects. At the same time, we need to create a model that is much closer to source code than the input AST.
The output model objects should have fields with all of the necessary information nicely computed. This will make it easier for target developers to see what information they have available. I.e., I'm not going to leave a grammar pointer as a field and expect people to know how to ask the grammar for the various elements. I think I should compute everything that could become an attribute in the output template. Should isolate target developers from internal ANTLR data structures
even if it means copying some data around. E.g., copy modifiers on rule to InvokeRule object as Strings not GrammarAST nodes.
What are the output entities that comprise a parser?
- file
- parser
- token type and name definitions
- list of imported parser objects
- list of parser objects that import us
- rule functions
- bit set definitions
- DFA definitions
- scope definitions
- member code (and other named actions)
Within rule functions, we have
- token references
- rule references
- list of elements used in tree construction rewrites (after '->')
- list of labels used within rule function
- make root, add leaf operations
- save result as label
- add result to list label
- dbg event instructions
- sync calls for error recovery
- optional blocks (with variations for LL(1) etc.)
- * loops
- + loops
- actions
Here in the hierarchy that I have been playing with:
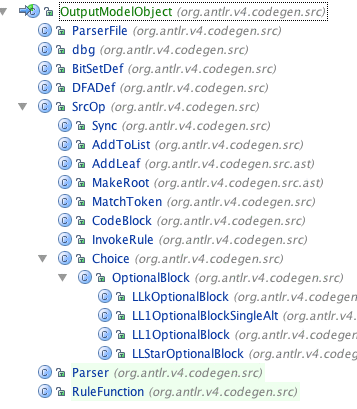
From all of this, target developers be able to construct output. They are free to define anything they need for their support to such as predefined labels in a rule function and so on.
It seems like we should keep templates out of the output model objects. Those output model objects are really about computing all of the necessary elements for any kind of final instruction generator. They are like adapter objects. They should not get caught up in creating templates. For one thing, that means a target developer can do something really complicated if they want by writing Java code instead of building templates.
Compilers use low-level ASTs consisting of simple operations like load and store. From there, they use a TWIG/BURG (optimal tree-walking instruction generator) to map AST subtrees to instructions. The AST in ANTLR is too high level for code generation purposes; we need something a little bit closer to the output not the input. That will be the role of the output object models. The mapping from output model object to template is likely one-to-one so we don't really need a sophisticated output model walker. Still, I think the separation would be nice if we had an independent external mapping from model to template. This literally could be as simple as a Java Map<OutputModelObject, String>.
Pushing in one arg to each template lets me change model w/o breaking everyone's output templates.
I am liking this output model thing. As we construct a model, type system really helps us understand what's going on. ST objects aren't as helpful because they are untyped. For example, it's going to be easy to do a Passover the output model tree to look for cases where we can flip match to consume. These output models also provide a convenient place to specify everything associated with a kind of output constructs such as LL1Optional or LL1OptionalSingleAlt. My output model walker automatically associates a template with each output model, one-to-one with the name. the list of template arguments after the initial output model argument indicates which sub elements Walker should examine.
Using constructors to do a lot of work during output model construction. It turns out that this is not a good idea for complicated translations. Well, it should at least not descend into its contained output model objects. Otherwise, a call to the constructor of the root object does the entire construction of the output model. sounds like an okay idea until you realize that many of the deeply nested output model construction mechanisms will need to communicate with contact information. Another words, when you are deeply nested in a rule and need to reference a bit set, you have to tell the outer parser output model object to define a new bit set. so we create a reference to it in a deeply nested computation and need to notify a previous object. If that object has not completed its constructor call yet, it's challenging to get a pointer to it in order to notify it of the new bits set. If we have a factory, we need to track various context pointers:
class OutputModelFactory:
OutputModelObject root;
Parser currentParser;
...
root = new ParserFile(...); // constructs everything before we set root
// meaning that no one can reference root etc...
There are two things you need to do in order to perform a translation:
- You need to map an input construct, a set of constructs, or abstraction into an output model object or set of objects. This is the key to input to output construct translation
- You need a mechanism to render output model objects as text, usually with a template engine to avoid model view entanglement
Sometimes these are combined because we can directly map an input construct to an output template. In this case, the output template serves as both the output model and the rendering object. For complicated translations like ANTLR, we need to separate the two because:
- it's nice to provide the set of output model object in order to notify target developers set of information they have available. In previous versions, target developers had to look at the internal data structures of ANTLR's analysis engine to figure out what they had available to them as output elements.
- typically we need to compute output model elements; they don't have to be just copies of information from the analysis. Templates don't do any computation so that means we would need to clutter the input pattern recognizer with the output model computations.
- there might be more than one way to translate an input construct; we need to right code to choose the appropriate output model. Again, we don't want to clutter the pattern recognizer with this information.
- Each input construct might yield multiple output objects. For example, the single input construct "match token" yields a single output object called MatchToken unless we are building trees and perhaps debugging. In some cases we might need three or four instructions.
Speaking of generating multiple instructions, sometimes we can simply return more than one instruction for each input construct recognition such as " match token" and sometimes we need to send to structure this to distant locations within the tree of output model objects. As I talked about above, you need to track context pointers as we descend into the output constructs. We can then notify the current rule or current instruction block about new instructions.
here's the basic infrastructure. I need to do computations in order to create the attributes of output model objects. These computations might yield more than one output model and might modify distant locations in the tree. Each output object should go to a single output template; there is really no competition here, just a way to render the output elements. my output model walker handles this automatically, which is a good idea so that I don't have to build a visitor manually that goes down through all of the heterogeneous nodes. By keeping the computations out, this dramatically simple five the output templates because target developers don't have to figure out when to generate AST construction instructions and so on. they simply define what those canonical operations are and the code generator will decide which instructions are necessary. It might be okay to have constructors build the attributes for the object I asked for, but it should not descend into a nested elements. We need to trigger the nested objects with another function defined within the output model class hierarchy such as build() or something. Because I don't no information has to be passed down to these nested output model object constructors, I can't build a walker that automatically constructs the tree. the code that descends into nested elements (such as the code block within a (...)* output model) should be moved to the build() method.
The pattern match her for the grammar AST should trigger calls like "heh I found this input construct called Token reference". Within that call in some factory, I create the necessary operations such as MatchToken and MakeRoot. Each call to the factory can potentially return multiple instructions so all of the factory methods return a tuple or list. I will have to experiment with which is better. Java definitely does not make returning multiple objects easy.
Ok, actually it's okay to use the constructor to create all the sub elements. I can set context pointers in the constructors as I go down. For example, in the rule invocation output model object, I can push the rule as the current rule context pointer.
we do need, however, that output model factory that knows how to create multiple output object for a single input construct such as for matched token. The key is to have each output model object be completely self-contained as a canonical operation. For example, a while loop might need a temporary variables for its expression such as the first symbol of lookahead. We should define that within the output model object and output template for that single while construct rather than returning multiple instructions. part of the reason is that we need to insert an assignment to set the value inside the loop. It's best that we handle everything within that loop rather than insert an instruction within the loop and also return a declaration object in front of the while.
public LL1PlusBlockSingleAlt(OutputModelFactory factory, GrammarAST blkAST, List<CodeBlock> alts) {
super(factory, blkAST, alts);
IntervalSet loopBackLook = altLookSets[2]; // loop exit is alt 1
expr = factory.getLL1Test(loopBackLook, ast);
if ( expr instanceof TestSetInline ) {
TestSetInline e = (TestSetInline) expr;
Decl d = new TokenDecl(e.varName);
addPreambleOp(d);
CaptureNextToken nextToken = new CaptureNextToken(e.varName);
addPreambleOp(nextToken);
addIterationOp(nextToken);
iteration = new ArrayList<SrcOp>();
iteration.add(nextToken);
}
}
actually, sometimes it's difficult to set a context pointer. At least, when we build things bottom-up such as code blocks. How can we set the current surrounding code block when that object is constructed until all of the pieces have been built. But it is those very pieces that need to add declarations and so on at the start of the code block. The only solution is to create a buffer of elements that need to be inserted at the front. So, in this case, if I need to add declarations to the start of the rule's code block, I can simply create a list of preamble instructions in the current rule. Once I've created the code block I can insert them at the front.