This doc has moved to the github.com/antlr/jetbrains repo
https://raw.githubusercontent.com/antlr/jetbrains/master/doc/plugin-dev-notes.md
Useful projects
https://github.com/nicoulaj/idea-markdown
PSI
Parse trees versus PSI trees versus element types
[Note: The documentation and class hierarchy is a bit confusing because the root of all this stuff is ASTNode for both parse tree nodes and PSI nodes. The documentation calls the parse tree an AST, which is very misleading. It should strictly be parse tree or syntax tree. The PSI tree is actually the abstract syntax tree (AST) in typical literature. The ASTFactory seems to create parse tree internal nodes and leaves that can be psi or parse tree nodes. For example, the CoreASTFactory creates LeafPsiElement nodes by default.]
A lexer creates tokens (PsiBuilderImpl.Token) with specific token types, identified by IElementType. A parser creates a parse tree whose internal nodes are also identified by certain types that derive from IElementType as well. For example, consider assignment like "x = 3;" for which we might create IElementType instances for the identifier, =, the integer and the ;. Further, we might create a subclass of IElementType called AssignmentNode to identify the syntactic structure (an internal parse tree node type). The parse tree or syntax trees are built for the entire file.
A PsiBuilder is used by the parser to create parse trees. It indicates the start and stop of grammatical constructs such as assignments and methods using a PsiBuilder.Marker by calling mark() and done(IElementType). The tokens matched by builder.advanceLexer() in between mark and done become children of the current marker (internal parse tree boundaries).
From a parse tree, the API wants to create an abstract syntax tree called a PSI tree that typically mirrors the parse tree by creating ASTWrapperPsiElement instances that refer to the original parse tree nodes from which the PSI nodes were created. This is generally done through the factory method createElement() in ParserDefinition:
/** Convert from parse node (AST they call it) to final PSI node. This
* converts only internal rule nodes apparently, not leaf nodes. Leaves
* are just tokens I guess.
*/
public PsiElement createElement(final ASTNode node) {...}
The API says to ensure there is a single kind of PSI node type for each parse tree node type.
* !!!WARNING!!! PSI element types should be unambiguously determined by AST node element types.
* You can not produce different PSI elements from AST nodes of the same types (e.g. based on AST node content).
* Typically, your code should be as simple as that:
*
* if (node.getElementType() == MY_ELEMENT_TYPE) {
* return new MyPsiElement(node);
* }
The PSI gets replaced for the changed parts of the parse tree as we edit source code.
An ASTFactory indicates how to create parse tree nodes from token and parse markers. The builder knows to call createLeaf() for tokens and createComposite() for internal parse tree nodes. The CoreASTFactory creates LeafPsiElement nodes by default unless we create a new factory. That means that the factory is actually creating PSI nodes for leaves by default. In createLeaf(), here is how I create a PSI node using the ASTFactory:
if ( type.toString().equals("ID") ) {
return new IDRefElement(type, text);
}
The PsiViewer plug-in then shows nodes like IDRefElement(ID) instead of PsiElement(ID).
Unless you need special parse tree nodes, you can ignore createComposite(). You have an opportunity in createElement() from the parser definition object to convert internal parse tree nodes to PSI nodes.
Register a new factory via plugin.xml:
<lang.ast.factory language="Simple" implementationClass="com.simpleplugin.SimpleASTFactory"/>The XmlASTFactory creates elements that are derived from CompositePsiElement such as XmlDeclImpl and XmlEntityDeclImpl. For leaves, it creates XmlTokenImpl instances, which are LeafPsiElement.
It's nice to have the class hierarchy handy:

Stubs
http://confluence.jetbrains.com/display/IDEADEV/Indexing+and+PSI+Stubs+in+IntelliJ+IDEA
Demitry slides:
Compact binary serialization of externally visible interface of file. Must be sufficient for resolving imported declarations without parsing imported files. Psi elements can exist in two modes: stub-based and AST-based.
Demitry forum:
The whole point of having stubs is that you can have a PSI tree which is backed by stubs rather than complete PSI elements. Your PSI element implementation should provide as much information as possible based on stubs (for example, something like MyClass.getName() should take the name from the stub and return it, rather than finding the name identifier node and returning its text). If your implementation accesses the AST, it will be parsed and provided for you transparently, but unnecessary AST access makes stub implementation far less efficient than it could be.
A stub has a number of keys that can get us to psi elements we might need for jumping to classes or whatever.
Question: Why does Java's PsiModifierListImpl implement JavaStubPsiElement?
Lexers
...
Colin: "the parsing lexer still has to return tokens that completely cover the file (i.e. no gaps). This is one of the most significant differences from a traditional compiler parser/lexer. That might be the cause of your segment errors if you're not doing that."
I had a problem getting an index out of bounds exception when deleting a character in the input; I had the following sample input for my ANTLR plug-in:
parser [grammar T;a : ID;and got this error when I tried to backspace over the leftbracket:
| Code Block |
|---|
java.lang.IndexOutOfBoundsException: Wrong offset: 8. Should be in range: [0, 7]
at com.intellij.openapi.editor.ex.util.SegmentArray.findSegmentIndex(SegmentArray.java:96)
at com.intellij.openapi.editor.ex.util.LexerEditorHighlighter.documentChanged(LexerEditorHighlighter.java:227)
at com.intellij.openapi.editor.impl.DocumentImpl.changedUpdate(DocumentImpl.java:592)
at com.intellij.openapi.editor.impl.DocumentImpl.access$600(DocumentImpl.java:51)
at com.intellij.openapi.editor.impl.DocumentImpl$MyCharArray.afterChangedUpdate(DocumentImpl.java:881)
at com.intellij.openapi.editor.impl.CharArray.remove(CharArray.java:286)
at com.intellij.openapi.editor.impl.DocumentImpl.deleteString(DocumentImpl.java:374)
at com.intellij.openapi.editor.actions.BackspaceAction.doBackSpaceAtCaret(BackspaceAction.java:104)
... |
It turns out that I had a lexical mode for [...] arg actions that did not take into consideration EOF before seeing the ]. The ANTLR lexer returned token:
[@-1,7:26='[grammar T;\n\na : ID;',<-1>,1:7]
where <-1> means EOF token type. So the intellij lexer decided that there was no more input or something after index 7. When I delete the [, all of a sudden, there is a bunch more input. The key is to always account for all of the input with the token set sent to the highlighter etc...
The dreaded "IntellijIdeaRulezzz" string
http://devnet.jetbrains.com/thread/454069?tstart=0
Colin Flemin: That string is inserted during completion, to ensure that there's always a valid identifier at the caret when running completion. You can customise it to whatever would be a valid identifier in your language, but generally you need something (i.e. you can't customise it to insert an empty string, as Sam tried). The way this works is during completion the PSI is copied and that symbol is inserted into the copy. You then do your autocomplete logic but that symbol is never inserted into your original document. The only way it sneaks into the real document is generally bugs in the autocomplete code, i.e. creating an autocomplete item from the dummy symbol.
The token is inserted to make autocomplete logic more consistent - often autocomplete needs to take into account the surrounding context and without an identifier there that context is often invalid. Imagine that I'm completing a static method call in Java, say Integer.parseInt(). If I have the Integer.| (with | representing the cursor) that's going to be an invalid chunk of code which would complicate the completion - having Integer.IntelliJRulezz at least makes the immediate context for completion a valid identifier, even though it's a little nonsensical.
Jon Acktar: The token is inserted into a copy of the file, so your lexer gets to lex your original and the copy at the same time, since you have probably typed something in the original document the original gets reprocessed by the lexer along with the copy that has been made. So during completion there are 2 copies of the file, one with the string and one without.
Maybe my solution is to simply ignore errors from a lexer working on the copy? For my particular problem at the moment, I'm building an input window for the ANTLR plug-in, for which I do not need auto completion so I can simply ignore that lexer maybe. This behavior would explain why I saw more lexing requests than I thought were needed.
It looks like the second lexer/parser is invoked from CompletionAutoPopupHandler.invokeCompletion() when there is that strange string on there. I am altering my parser definition object to return an empty lexer and empty parser when I detect that string.That did not work. You have to make the lexer skip the strange string first. The character input stream sets the end offset to the start of that dummy string. That way the lexer never sees it. Two parsers are created, one for the auto completion process and it contains the dummy string. All we have to do is avoid setting the visual parse tree to that particular parse tree. a parse errors that come from that we don't care about. I have no idea why it is calling the auto complete when I have all that turned off.
I gave up on this and simply spent a few hours getting my own error annotations added to a standard editor window based upon ANTLR parsing. Much easier than figuring out the quirky and finicky parsing infrastructure within intellij.
Turning off auto completion lexing
In the end it became clear that we cannot turn this off because other plug-ins might need it. I'm not sure this will work anyway.
Peter Gromov: You can turn autopopup completion off by providing a CompletionConfidence extension (with order="first"). You can also change the dummy identifier to something your lexer can handle (maybe even empty): com.intellij.codeInsight.completion.CompletionInitializationContext#setDummyIdentifier, com.intellij.codeInsight.completion.CompletionContributor#beforeCompletion
Custom Structure view.
Hook in a StructureViewBuilderProvider via plugin.xml:
<structureViewBuilder factoryClass="org.antlr.jetbrains.st4plugin.structview.STGroupStructureViewBuilderProvider"/>
See https://devnet.jetbrains.com/message/5564298 and https://devnet.jetbrains.com/thread/475435?tstart=0
public class STGroupStructureViewBuilderProvider implements StructureViewBuilderProvider {
@Nullable
@Override
public StructureViewBuilder getStructureViewBuilder(@NotNull FileType fileType, @NotNull VirtualFile file, @NotNull Project project) {
return new STGroupStructureViewBuilder();
}
}
public class STGroupStructureViewBuilder implements StructureViewBuilder {
@NotNull
@Override
public StructureView createStructureView(FileEditor fileEditor, Project project) {
return new STGroupStructureView();
}
}
...
}...
...
}
You also need to invalidate tree upon editor changes
/** Invalidate tree upon doc change */
public void registerStructureViewModel(final Editor editor, final STGroupStructureViewModel model) {
final Document doc = editor.getDocument();
final DocumentListener listener = new DocumentAdapter() {
@Override
public void documentChanged(DocumentEvent e) { model.invalidate(); }
};
DocumentListener oldListener = doc.getUserData(EDITOR_STRUCTVIEW_LISTENER_KEY);
if ( oldListener!=null ) {
doc.removeDocumentListener(oldListener);
}
doc.putUserData(EDITOR_STRUCTVIEW_LISTENER_KEY, listener);
doc.addDocumentListener(listener);
}
In the view model, we set
/** force rebuild; see {@link #getRoot()} */
public void invalidate() {
parseTree = null;
}
/** If parseTree==null, this will return a StructureViewTreeElement with
* getValue()==null, which forces rebuild in {@link com.intellij.ide.impl.StructureViewWrapperImpl#rebuild()}
*/
@NotNull
@Override
public StructureViewTreeElement getRoot() {
return new STGroupRootStructureViewTreeElement(parseTree,file);
}
Resolving references
All PsiElement can getReference() and getReferences() which return PsiReference. That reference can really be anything we want. I see PsiBreakStatementImpl returning a PsiLabelReference that wraps the break statement and the identifier in the break statement.
The main method of the PsiReference interface is resolve(), which returns the element to which the reference points, or null if it was not possible to resolve the reference to a valid element (for example, it points to an undefined class).
The PsiLabelReference is really just a wrapper for the source and target as well as the key resolve() method that actually looks for the identifier by walking up the parents in the PSI tree. It looks at each statement in the outer context and checks to see if it's labeled:
| Code Block |
|---|
@Override
public PsiElement resolve(){
final String label = myIdentifier.getText();
if(label == null) return null;
PsiElement context = myStatement;
while(context != null){
if(context instanceof PsiLabeledStatement){
final PsiLabeledStatement statement = (PsiLabeledStatement) context;
if(label.equals(statement.getName()))
return statement;
}
context = context.getContext();
}
return null;
} |
Ok, here's a skeleton for a PsiReference
| Code Block |
|---|
/** A pair that indicates PSI Node idNode has an identifier called id.
* This class should be able to resolve by looking for id up the tree.
*/
public class IDPsiReference extends PsiReferenceBase<IDRefElement> {
String id;
/** Create a ref from idNode with text id */
public IDPsiReference(IDRefElement idNode, String id) {
super(idNode, new TextRange(0, id.length()));
this.id = id;
}
@Override
public PsiElement bindToElement(@NotNull PsiElement element) throws IncorrectOperationException {
System.out.println("bindToElement: "+element);
return null;
}
/** Called upon "jump to def" */
@Nullable
@Override
public PsiElement resolve() {
System.out.println("resolve: "+id);
return myElement; // resolve to self
}
@NotNull
@Override
public Object[] getVariants() {
return ArrayUtil.EMPTY_OBJECT_ARRAY;
}
} |
It is created and returned by
| Code Block |
|---|
public IDPsiReference getReference() {
System.out.println("getReference: "+this.toString());
return new IDPsiReference(this, getText());
} |
within my
class IDRefElement extends LeafPsiElement implements PsiNamedElementAnnotators
If you ever want to do something or check something on every leaf node in a PSI tree, you want an annotator. There is an example here:
http://confluence.jetbrains.com/display/IntelliJIDEA/Annotator
Annotator helps highlight and annotate any code based on specific rules.
Doc:
The third level of highlighting is performed through the Annotator interface. A plugin can register one or more annotators in the com.intellij.annotator extension point, and these annotators are called during the background highlighting pass to process the elements in the PSI tree of the custom language. Annotators can analyze not only the syntax, but also the semantics of the text in the language, and thus can provide much more complex syntax and error highlighting logic. The annotator can also provide quick fixes to problems it detects.
There is also the notion of an external annotator that is run after all other internal annotators have executed. See API doc below.
Here's a basic starter kit. Add this to the plugin.xml file under extensions:
<annotator language="MyLang" implementationClass="com.mylangplugin.annotation.MyLangAnnotator"/>Then create a bare-bones annotator
| Code Block |
|---|
import com.intellij.lang.annotation.AnnotationHolder;
import com.intellij.lang.annotation.Annotator;
import com.intellij.psi.PsiElement;
import org.jetbrains.annotations.NotNull;
public class MyLangAnnotator implements Annotator {
@Override
public void annotate(@NotNull PsiElement element, @NotNull AnnotationHolder holder) {
System.out.println("annotate: "+element);
}
} |
Given my PSI tree:
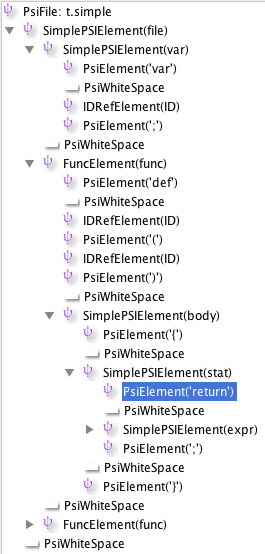
I get a call to each of my leaf nodes, not the internal nodes.
annotate: PsiElement('var')
annotate: PsiWhiteSpace
annotate: IDRefElement(ID)
annotate: PsiElement(';')
annotate: SimplePSIElement(var)
annotate: PsiWhiteSpace
annotate: PsiElement('def')
annotate: PsiWhiteSpace
annotate: IDRefElement(ID)
...
NOTE: the language you specified in the XML is important. For example in that link above, they try to resolve properties in JAVA files:
<annotator language="JAVA" implementationClass="com.simpleplugin.SimpleAnnotator"/>We can use it to check type information or for undefined variables and that sort of thing. If we find that there is a problem with an identifier, for example, we can flip the text color to red or something. The SimpleAnnotator given for JAVA, does this:
TextRange range = new TextRange(element.getTextRange().getStartOffset() + 8, element.getTextRange().getEndOffset());holder.createErrorAnnotation(range, "Unresolved property");Inspections vs Annotators
Forum thread on inspections versus annotators:
If you need the ability to perform the analysis for multiple files in batch mode (Analyze | Inspect Code), use LocalInspectionTool. Otherwise, use Annotator. Annotator gives you more flexibility in reporting the problems (with highlight, custom tooltips and so on), and better locality (for custom languages, LocalInspectionTool is always called to reinspect the entire file, while Annotator is called only for changed fragments of the PSI tree).
I think a good rule is, if it's an error or semantic highlighting, use annotator; if it's a warning, use inspection.
There is also the ExternalAnnotator, which I have mentioned below. I would say it is more useful when you have an existing compiler and you want to highlight stuff in the editor.
Colin Fleming: You can create info annotations that don't show in the editor but have tooltips, I think, although I haven't tried that.
Misc PSI stuff
You can associate data with the PSI element using get/putUserData.
Popups
popup code examples and intellij "doc"
...
Balloons
| Code Block |
|---|
BalloonBuilder builder =
JBPopupFactory.getInstance().createHtmlTextBalloonBuilder("hello", MessageType.INFO, null);
Balloon balloon = builder.createBalloon();
RelativePoint where = new RelativePoint(mouseEvent.getComponent(), point);
balloon.show(where, Balloon.Position.above); |
Hints / tooltip above cursor
| Code Block |
|---|
caretModel.moveToOffset(offset); // tooltip only shows at cursor if info hint :(
HintManager.getInstance().showInformationHint(editor, tokenInfo); |
Error tooltip above cursor
| Code Block |
|---|
int flags =
HintManager.HIDE_BY_ANY_KEY |
HintManager.HIDE_BY_TEXT_CHANGE |
HintManager.HIDE_BY_SCROLLING;
int timeout = 0; // default?
HintManager.getInstance().showErrorHint(editor, errorDisplayString,
offset, offset + 1,
HintManager.ABOVE, flags, timeout); |
Documents etc...
Get text from current open file
http://stackoverflow.com/questions/17915688/intellij-plugin-get-code-from-current-open-file
Commit vs save
http://devnet.jetbrains.com/message/3436303#3436303
1. VFS (Virtual File System) mirrors physical file system and represents raw data being stored on hard disk/network drive/zip or jar file
2. Document stores raw character data of the text files being edited by means of Editor (user typings etc.) or PSI (refactorings for example). Doesn't have to be intact with VFS until saved (action that propogates data from document to file system) or reload (action that propogates data from filesystem to the document).
3. PSI (Program Structure Interface) mostly represents AST (abstract syntax tree). Changes made to PSI (through various setters and other write interface) are immediately propogated to the Document while changes made to the Document (by means other than PSI, Editor for example) are propogated to PSI via commitDocument action (an AST getting reparsed that time).
Editor stuff is much simpler actually.
The Editor itself is just text editor component which is able to edit data
contained in the Document. Thus editor is a View and Controller of the Document
(model). In fact, this pair not only used for editing files but in many other
places like console view, diff panel, live and file template configuration
and even various text fields that support completion and validation stuff.
FileEditor is something that represent abstaction of the editor tab.
TextEditor is a special case of the FileEditor that wraps Editor thus representing
editor tab for editing text files. Other cases of the FileEditors come into
my mind are: UI Designer forms editor, various J2EE deployment descriptior
visual editors.
Listen for key presses in editor
editor.getContentComponent().addKeyListener(
new KeyAdapter() {
@Override public void keyTyped(KeyEvent e) {
super.keyTyped(e);
}
}
);
Save file
| Code Block |
|---|
FileDocumentManager docMgr = FileDocumentManager.getInstance();
Document doc = docMgr.getDocument(file);
docMgr.saveDocument(doc); |
Commit changes to file to PSI tree
| Code Block |
|---|
// Commit changes to file to PSI tree; does NOT write to disk
Project project = ANTLRv4ProjectComponent.getProjectForFile(virtualFile);
PsiDocumentManager docMgr = PsiDocumentManager.getInstance(project);
Document doc = docMgr.getDocument(file);
docMgr.commitDocument(doc); |
Listen for doc changes
Well, I'm not sure what the intended sequence is, but I spent the time to read through the code and I see the following sequence in FileEditorManagerImpl.openFileImpl4():
| Code Block |
|---|
getProject().getMessageBus().syncPublisher(FileEditorManagerListener.Before.FILE_EDITOR_MANAGER).beforeFileOpened(this, file);
window.getOwner().setCurrentWindow(window, focusEditor);
[...].fileOpened(FileEditorManagerImpl.this, file); |
so it looks like before file opened, selection changed, file opened. I guess this makes sense. the file opened his notifying us after the fact that the selection changed event had to open the file and display it. I think the before file opened event is the one I want.
from looking at the code, before file opened does *not* it triggered if someone simply switches tabs, which is what I want. When the selection changed event occurs, the code makes it look like everything is been set up.
| Code Block |
|---|
doc.addDocumentListener(new DocumentListener() {
@Override
public void beforeDocumentChange(DocumentEvent event) {}
@Override
public void documentChanged(DocumentEvent event) {
System.out.println("doc changed");
}
}); |
listen for save file event
| Code Block |
|---|
MessageBusConnection msgBus = project.getMessageBus().connect(project);
msgBus.subscribe(VirtualFileManager.VFS_CHANGES, new BulkFileListener.Adapter() {
@Override
public void after(List<? extends VFileEvent> events) {
System.out.println("file changed");
}
}); |
looks like we use disconnect() to stop listening.
That seems to find changes with events.size() always 1. This one seems more direct.:
| Code Block |
|---|
VirtualFileManager.getInstance().addVirtualFileListener(new VirtualFileAdapter() {
@Override
public void contentsChanged(VirtualFileEvent event) {
final VirtualFile vfile = event.getFile();
}
}); |
Listen for change of editor window
| Code Block |
|---|
// Listen for editor window changes, must notify preview tool window
MessageBusConnection msgBus = project.getMessageBus().connect(project);
msgBus.subscribe(FileEditorManagerListener.FILE_EDITOR_MANAGER,
new FileEditorManagerListener() {
@Override
public void fileOpened(FileEditorManager source, VirtualFile file) {
}
@Override
public void fileClosed(FileEditorManager source, VirtualFile file) {
}
@Override
public void selectionChanged(FileEditorManagerEvent event) {
System.out.println("changed");
}
}); |
Create an editor not from a file but from text.
See http://devnet.jetbrains.com/message/5480913#5480913
| Code Block |
|---|
final EditorFactory factory = EditorFactory.getInstance();
final Document doc = factory.createDocument(inputText);
LightVirtualFile vf =
new LightVirtualFile(grammarFileName + ".parser-input",
PreviewFileType.INSTANCE,
inputText);
FileDocumentManagerImpl.registerDocument(doc, vf);
ApplicationManager.getApplication().runReadAction(
new Runnable() {
@Override
public void run() {
editor = factory.createEditor(doc, project, PreviewFileType.INSTANCE, false);
}
}
); |
Get virtual file from an editor or document
It took me forever, but I finally figured out that you can't ask an editor or word document for its associated file. You have to ask the FileDocumentManager:
| Code Block |
|---|
Document doc = e.getEditor().getDocument();
VirtualFile vfile = FileDocumentManager.getInstance().getFile(doc); |
Get editor from a virtual file
| Code Block |
|---|
final Document doc = FileDocumentManager.getInstance().getDocument(previewState.grammarFile);
EditorFactory factory = EditorFactory.getInstance();
final Editor[] editors = factory.getEditors(doc, project);
Editor grammarEditor = editors[0]; // hope just one |
Listen for mouse events in an editor
There is no direct way to register the listeners because you don't have a hook to the editors so you can wait for editor creation via EditorFactory:
| Code Block |
|---|
EditorFactory factory = EditorFactory.getInstance();
factory.addEditorFactoryListener(
new EditorFactoryAdapter() {
@Override
public void editorCreated(@NotNull EditorFactoryEvent event) {
Editor editor = event.getEditor();
editor.addEditorMouseListener(
new EditorMouseAdapter() {
@Override
public void mouseEntered(EditorMouseEvent e) {
Document doc = e.getEditor().getDocument();
VirtualFile vfile = FileDocumentManager.getInstance().getFile(doc);
if ( vfile!=null ) {
System.out.println("entered editor frame");
}
}
}
);
}
}
); |
Get line/col from mouse event
In EditorMouseMotionListener.mouseMoved(final EditorMouseEvent e):
| Code Block |
|---|
MouseEvent mouseEvent = e.getMouseEvent();
Point point = new Point(mouseEvent.getPoint());
Editor editor = e.getEditor();
LogicalPosition pos = editor.xyToLogicalPosition(point);
int offset = editor.logicalPositionToOffset(pos);
int selStart = editor.getSelectionModel().getSelectionStart();
int selEnd = editor.getSelectionModel().getSelectionEnd(); |
Get offset from Action event (right click menu)
seems mouse event appears *after* update() in actionPerformed() however. :) So actionEvent.getInputEvent() will work in actionPerformed().
| Code Block |
|---|
Point mousePosition = editor.getContentComponent().getMousePosition();
LogicalPosition pos=editor.xyToLogicalPosition(mousePosition);
int offset = editor.logicalPositionToOffset(pos); |
Highlight region of editor text
Here is a way to do your own annotations without having to use the PSI infrastructure. See above for tooltips.
| Code Block |
|---|
// Underline
final TextAttributes attr=new TextAttributes();
attr.setForegroundColor(JBColor.BLUE);
attr.setEffectColor(JBColor.BLUE);
attr.setEffectType(EffectType.LINE_UNDERSCORE);
RangeHighlighter rangehighlighter=
markupModel.addRangeHighlighter(tokenUnderCursor.getStartIndex(), // char index in buffer
tokenUnderCursor.getStopIndex()+1,
0, // layer
attr,
HighlighterTargetArea.EXACT_RANGE); |
Actions, intentions, live templates
http://devnet.jetbrains.com/thread/454250
From Peter Gromov:
Live templates are code snippets, possibly with some placeholders, inserted into editor using Meta+J or (since IDEA 13.1) just code completion. They are invoked by entering their prefix.
Intentions are actions that can be invoked from editor by pressing Alt+Enter when a light bulb appears, indicating that the IDE can do something automatically for you at this position. Common cases are simple code transformations (De Morgan laws, condition invesion etc).
Actions are... well, actions. Things that can be invoked, most often from a menu or a toolbar. Or via a shortcut. They all can be found in Meta+Shift+A (Go To Action).
When you generate a constructor, you're using Generate action (probably invoked with a shortcut). In fact it's an ActionGroup (composite action) containing other actions: for constructor, getters/setters, equals/hashCode. A plugin can also contribute its own actions to that list.
What should you use? I don't know. It's mostly a question of UX. All these things can be used to achieve the same. Live templates are most declarative of all, so the possibilities are restricted there. But they might well be sufficient for your task. And they can be modified by user, which it harder with other things. Actions are as discoverable as you place them in UI. Live templates pop up in autocompletion, so the users will probably notice them. Intentions or Generate actions are more hidden, but are more powerful than live templates. And you should also consider what the best way to invoke your functionality should be. A string in the editor? Alt+Enter? Generate? A shortcut? It's for you to decide
Alan Foster:
You can register with the fileTemplateGroup extension point, and then your users will be able to create a new file from a given set of templates.
The file templates are pretty powerful too, as they allow you to use velocity directives, so you can generate most things in a file too
This might be useful if there's a default ANTLR file you want users to be able to start from, and also provide a bunch of different base files to choose from

Live templates
There is OpenAPI for providing Live Template functions. One can create IntelliJ IDEA plug-in that will add more functions.
See the Macro abstract class. Plug-in should define extension point, like this one:
<liveTemplateMacro implementation="com.intellij.codeInsight.template.macro.CapitalizeMacro"/><defaultLiveTemplatesProvider implementation="com.intellij.codeInsight.template.impl.JavaDefaultLiveTemplatesProvider"/>how to use the new live templates API?
http://devnet.jetbrains.com/message/5223260#5223260
embed a custom live template in a plugin
http://devnet.jetbrains.com/message/5508933
You can edit with intellij then pick up from file (on Mac):
/Users/YOUR_USER_ID/Library/Caches/IdeaIC12/plugins-sandbox/config/templates/user.xml
Sample
| Code Block |
|---|
<liveTemplateContext implementation="org.antlr.intellij.plugin.templates.ANTLRGenericContext"/>
<liveTemplateContext implementation="org.antlr.intellij.plugin.templates.OutsideRuleContext"/> |
| Code Block |
|---|
public class ANTLRGenericContext extends ANTLRLiveTemplateContext { // this gives us an ANTLR main menu in context popup.
public ANTLRGenericContext() {
super("ANTLR", "ANTLR", EverywhereContextType.class);
}
@Override
protected boolean isInContext(@NotNull PsiFile file, @NotNull PsiElement element, int offset) {
return true;
}
} |
| Code Block |
|---|
public abstract class ANTLRLiveTemplateContext extends TemplateContextType {
public ANTLRLiveTemplateContext(@NotNull @NonNls String id,
@NotNull String presentableName,
@Nullable Class<? extends TemplateContextType> baseContextType)
{
super(id, presentableName, baseContextType);
}
protected abstract boolean isInContext(@NotNull PsiFile file, @NotNull PsiElement element, int offset);
@Override
public boolean isInContext(@NotNull PsiFile file, int offset) {
// offset is where cursor or insertion point is I guess
if ( !PsiUtilBase.getLanguageAtOffset(file, offset).isKindOf(ANTLRv4Language.INSTANCE) ) {
return false;
}
if ( offset==file.getTextLength() ) { // allow at EOF
offset--;
}
PsiElement element = file.findElementAt(offset);
System.out.println("element " + element +", text="+element.getText());
if ( element==null ) {
return false;
}
return isInContext(file, element, offset);
}
} |
| Code Block |
|---|
public class OutsideRuleContext extends ANTLRLiveTemplateContext {
public OutsideRuleContext() {
// using ANTLRGenericContext means this will appear in submenu of ANTLR for "where this applies" in editor
super("ANTLR_OUTSIDE", "Outside rule", ANTLRGenericContext.class);
}
@Override
public boolean isInContext(@NotNull PsiFile file, PsiElement element, int offset) {
// System.out.println("offset="+offset);
CommonTokenStream tokens = ANTLRv4ParserDefinition.tokenize(file.getText());
Token tokenUnderCursor = ANTLRv4ParserDefinition.getTokenUnderCursor(tokens, offset);
// System.out.println(tokenUnderCursor);
int tokenIndex = tokenUnderCursor.getTokenIndex();
Token nextRealToken = ANTLRv4ParserDefinition.nextRealToken(tokens, tokenIndex);
Token previousRealToken = ANTLRv4ParserDefinition.previousRealToken(tokens, tokenIndex);
if ( nextRealToken==null || previousRealToken==null ) {
return false;
}
...
}
} |
| Code Block |
|---|
public class ANTLRLiveTemplatesProvider implements DefaultLiveTemplatesProvider {
// make sure module shows liveTemplates as source dir or whatever dir holds "lexer"
public static final String[] TEMPLATES = {"lexer/user"};
@Override
public String[] getDefaultLiveTemplateFiles() {
return TEMPLATES;
}
@Nullable
@Override
public String[] getHiddenLiveTemplateFiles() {
return new String[0];
}
} |
In directory %project%/resources/liveTemplates/lexer/user.xml:
| Code Block |
|---|
<?xml version="1.0" encoding="UTF-8"?>
<templateSet group="user">
<template name="id" value="ID : [a-zA-Z_]* [a-zA-Z0-9_]+ ;" description="Create identifier rule" toReformat="false" toShortenFQNames="true">
<context>
<option name="ANTLR_OUTSIDE" value="true" />
</context>
</template>
</templateSet> |
Make sure %project%/resources/liveTemplates is a source directory in your module or it won't be copied to plugin.
Getting project from an event
Looks like event.getProject() can cause problems. I get "cannot share data context between Swing events" errors from DataManagerImpl$MyDataContext. Thread in forums has something uglier that works: event.getData(PlatformDataKeys.PROJECT).
GUI and threads, background tasks
When updating anything in gui, must use UI thread.
| Code Block |
|---|
ApplicationManager.getApplication().invokeLater(new Runnable() {...}) |
From a conversation with Peter Gromov
- when you are looking at psi tree stuff for reading, do a runReadAction, unless you're in an action invoked from EDT
- when modifying the PSI tree, do runWriteAction
- when you are likely not in a GUI thread and need to execute in a GUI thread, use ApplicationMgr.invokeLater
- when you are or likely are in a GUI thread but need to execute something that takes a while, use Task.Backgroundable. Task.Backgroundable will show a progress, either modal or in status bar. Do not use invokeLater as it will invoke your code on EDT again, just later, so the IDE will still freeze. Instead, use Application.executeOnPooledThread. But if it works with PSI, then things get complicated, because you need a read action, and while you're holding it, typing into the editor becomes impossible.
UIUtils.invokeLaterIfNeeded will run it immediately if you are in the GUI thread.
File open, editor tab changed events
http://devnet.jetbrains.com/message/5514276
Shutdown sequence
http://devnet.jetbrains.com/thread/454312?tstart=0
How to wipe out plugin sandbox
kill this: /Volumes/SSD2/Users/parrt/Library/Caches/IdeaIC12/plugins-sandbox
The Missing API javadoc
IElementType
class IElementTypeA token type and parse node type. This is not a token, but a token type. There must be a unique instance associated with each LuaElementType("Expression List"), for example. If you create multiple instances of LuaElementType("Expression List") then the api will not consider them equal. I create a hash table to map name to element type instance. tree nodes are created from IElementType. The type value is stored in TreeElement. So any parse tree node should derive from this class.
Derive your token types and internal parse tree nodes from this class. For example, you would have all of your keywords and simple tokens derive ultimately from this class as well as internal nodes like method definition, statement block, class definition.
ILazyParseableElementType
class ILazyParseableElementType extends IElementTypeA token type which represents a fragment of text (possibly in a different language)
which is not parsed during the current lexer or parser pass and can be parsed later when
its contents is requested.
Examples include Java doc and JavaFileElementType and TemplateDataElementType for template languages.
IStubFileElementType
class IStubFileElementType<T extends PsiFileStub> extends IFileElementType implements StubSerializer<T>IFileElementType appears to only be used by JavaFileElementType. Oh,That is a token type or an internal parse tree node type that indicates the source element is a file reference. It is a kind of ILazyParseableElementType.
PsiFile
interface PsiFile extends PsiFileSystemItem"A PSI element representing a file."
From IntelliJ IDEA Architectural Overview:
A PSI (Program Structure Interface) file is the root of a structure representing the contents of a file as a hierarchy of elements in a particular programming language. The PsiFile class is the common base class for all PSI files, while files in a specific language are usually represented by its subclasses. For example, the PsiJavaFile class represents a Java file, and the XmlFile class represents an XML file.
The root of your tree is a PsiFile. Your ParserDefinition has to supply it via:
PsiFile createFile(FileViewProvider viewProvider);For example,
@Override
public PsiFile createFile(FileViewProvider viewProvider) {
return new MyLanguagePSIFileRoot(viewProvider);
}
FileASTNode
interface FileASTNode extends ASTNodeTop-level node in AST, corresponds to PsiFile.
A parse tree node that eventually becomes a PsiFile. From PsiFile, we can get it back via:
FileASTNode getNode();PsiFileStub
interface PsiFileStub<T extends PsiFile> extends StubElement<T>, UserDataHolder
IStubFileElementType getType();
This is an object that wraps a root (PsiFile) node and turns it into a stub.
FileElement
class FileElement extends LazyParseableElement implements FileASTNodeA parse tree node created from a IFileElementType. In an ASTFactory, you might see
public CompositeElement createComposite(IElementType type) {
if (type instanceof IFileElementType) {
return new FileElement(type, null);
}
return new CompositeElement(type);
}
ASTNode
interface ASTNode extends UserDataHolderThe root of all trees seems to be interface ASTNode that has a particular type, whether that is a token type or an internal parse tree node:
IElementType getElementType();PSI is under ASTNode which is confusing because the documentation calls the parse tree and AST. I thought that the PSI shadowed the AST with pointers.
The ASTDelegatePsiElement has the shadow pointer to the parse tree:
public abstract ASTNode getNode();ASTFactory
class ASTFactoryKey methods include how to create a composite and a leaf node (and a lazy node, which is often a stub referring to another file). An example is the XmlASTFactory that creates XmlTokenImpl (subclass of LeafPsiElement) nodes via createLeaf() and internal nodes like XmlDocumentImpl via createComposite(). Both of those methods operate on an IElementType argument. The PsiBuilderImpl calls createLeaf() when it sees a token and calls createComposite for other parsed tree nodes. The builder calls insertLeaves() (private) to add parse tree nodes created from tokens, which calls createLeaf() eventually. The ParserDefinition.createElement() method converts these to PSI nodes.
ASTDelegatePsiElement
class ASTDelegatePsiElement extends PsiElementBaseBifurcates a wrapper around a parse tree node, ASTWrapperPsiElement, and a stub based PSI element. Both have a pointer to a parse tree node:
private volatile ASTNode myNode;The stub is really a placeholder for another file whereas the wrapper version points to a parse tree node directly.
A method that could be important if you are caching elements in your psi nodes:
public void subtreeChanged() { }In forum post on looking up variables using the annotator, Dimtry says in 2004:
What's common is the subtreeChanged() method which is available in all PSI elements which extend ASTDelegatePsiElement. The method is called when any element below this element is modified, and it is intended to be used to clear the caches stored directly in this element (as fields or user data).
If you're writing a custom language implementation and your cached data depends only on the data directly under your PSI element (e.g. you're caching the list of methods in a class), it's easier to clear caches in subtreeChanged(). If you depend on values outside of your PSI element, you need to use CachedValue or another caching mechanism.
ASTWrapperPsiElement
class ASTWrapperPsiElement extends ASTDelegatePsiElement
private final ASTNode myNode;
public ASTNode getNode() { return myNode; }
Implemented by keeping a pointer to the parse tree; In this mode the ASTWrapperPsiElement turns the parse tree into a shadow tree.
TreeElement
class TreeElement extends ElementBase implements ASTNodeAn element in a generic tree control displayed in the IDEA user interface.
ElementBase doesn't seem to have much to do with trees it seems more codesharing than organizational type. More like bookkeeping stuff rather than behavior of a particular node.
Underneath we have composite and leaf elements. The composite element seems to be interior nodes whereas the leaf elements are just that, leaves. They cannot add or do anything with children.
class LeafElement
class LeafElementLeafPsiElement
class LeafPsiElement extends LeafElement implements PsiElement, NavigationItemA leaf node that is also a psi node and a structure view element via NavigationItem
CompositeElementclass CompositeElementAn internal node to either a parse tree or a PSI tree. CompositePsiElement is a subclass that represents an internal PSI node.
StructureViewTreeElement
interface StructureViewTreeElement extends TreeElement, NavigatableAn element in the structure view tree model.
Describes an object that you can view in the structure window. For example Java fields classes and methods.
Annotator
interface Annotator
An object that responds to annotate calls to examine or alter highlighting and so on for all PSI leaves.
void annotate(@NotNull PsiElement element, @NotNull AnnotationHolder holder)The order of traversal is not guaranteed but it appears to be in input order. Each annotate is guaranteed to execute until completion. Annotation is done only on changed elements of the PSI tree when local changes are made in the edit window. Dimtry gives a typical approach:
Each time annotate() is called on a specific element, you can walk the tree up from it and see what names are defined there and whether they're being shadowed by the name of the current element. Of course, you can cache the list of names in each element; the cache needs to be cleared when IntelliJ IDEA calls PsiElement.subtreeChanged(). [parrt: Modified to subtreeChanged() from a correction in a different forum post.]
Dimtry says that you can create a special cache that has dependencies so one could keep a symbol table up to date I guess.
For a cached value created using CachedValuesManager, you specify the dependencies, and the value gets invalidated once any of the dependencies changes.
One could also keep information in a symbol table outside of the PSI nodes, but I'm still not sure how to keep a symbol table current given local changes that can be made in the editor. I'm thinking it would be easier to simply rebuild the symbol table by walking the entire tree. Who cares if it takes even two seconds to update the red markers for unknown variables and so on? Perhaps using an external annotator is the right idea.
ExternalAnnotator
abstract class ExternalAnnotator<InitialInfoType, AnnotationResultType>Implemented by a custom language plugin to process the files in a language by an external annotation tool. The external annotator is expected to be slow and is started after the regular annotator has completed its work.
Warning: the API has changed on this from a simple annotate() to a more complicated but more powerful mechanism. I don't see any obvious usages in the plug-ins of the new API but I will keep looking. Surprisingly, there is lots of documentation for this API. The sequence seems to be collectInformation(), doAnnotate(), apply(). I would say this is more useful when you have an existing compiler and you wanted to highlight stuff in the editor.
Doc:
if the custom language employs external tools for validating files in the language (for example, uses the Xerces library for XML schema validation), it can provide an implementation of the ExternalAnnotator interface and register it in com.intellij.externalAnnotator extension point. The ExternalAnnotator highlighting has the lowest priority and is invoked only after all other background processing has completed. It uses the same AnnotationHolder interface for converting the output of the external tool into editor highlighting.
Register with:
...